
«`html
Улучшение моделей генерации кода с помощью автоматизированной синтезы тестов и обучения с подкреплением
Модели генерации кода достигли значительного прогресса благодаря увеличению вычислительных мощностей и улучшению качества обучающих данных. Современные модели, такие как Code-Llama, Qwen2.5-Coder и DeepSeek-Coder, демонстрируют выдающиеся возможности в различных задачах программирования. Эти модели проходят предварительное обучение и дообучение с использованием обширных наборов данных кода из веб-ресурсов.
Проблемы в генерации кода
Несмотря на успехи, применение обучения с подкреплением (RL) в генерации кода все еще недостаточно исследовано. Главные проблемы связаны с:
- Сложностью в установлении надежных сигналов вознаграждения для генерации кода.
- Нехваткой обширных наборов данных кода с надежными тестовыми случаями.
Практические решения
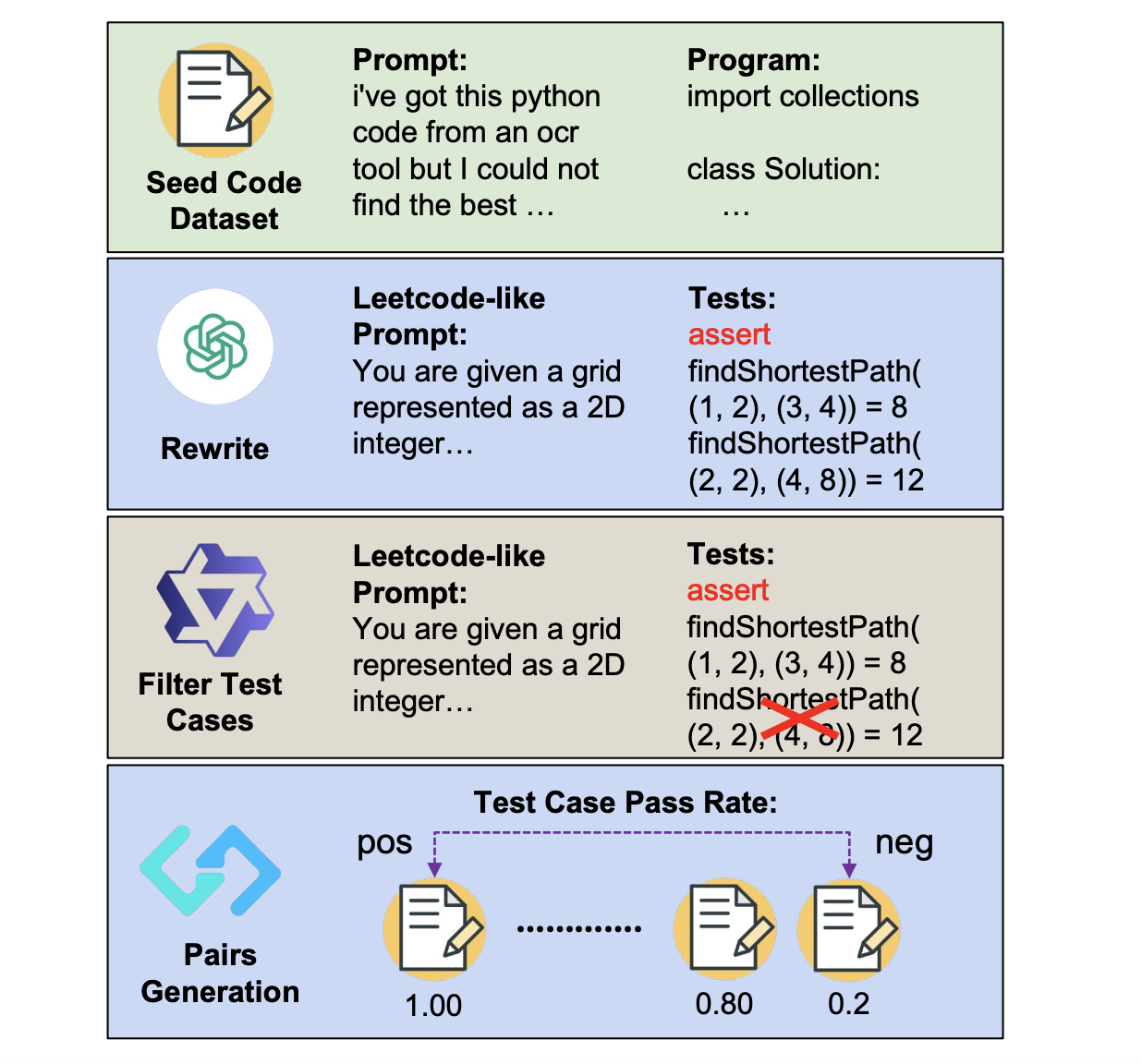
Ученые из Университета Ватерлоо и других исследовательских учреждений предложили новый подход для улучшения моделей генерации кода с использованием RL. Это включает:
- Автоматическую генерацию комплексных пар «вопрос-тест» из существующих данных кода.
- Использование коэффициентов прохождения тестов для создания пар предпочтений, которые затем используются для обучения моделей вознаграждения.
Этот метод продемонстрировал увеличение на 10 пунктов с моделью Llama-3.1-8B-Ins и улучшение на 5 пунктов с Qwen2.5-Coder7B-Ins, что позволяет 7B модели достичь уровня производительности более крупной модели 236B DeepSeekV2.5.
Экспериментальные детали
Эксперименты включают три основных этапа: обучение модели вознаграждения, обучение с использованием RL и настройка оценки. Модель Qwen2.5-Coder-7B-Instruct генерирует 16 ответов на каждый вопрос, что приводит к созданию около 300K пар предпочтений.
В ходе экспериментов ACECODE-RM значительно улучшает производительность моделей по сравнению с жадным декодированием, особенно в тестах HumanEval и MBPP. Например, на BigCodeBench-Full-Hard модель с правилами вознаграждения показывала улучшение на 3.4 пункта.
Заключение
Работа представляет первый автоматизированный подход к синтезу тестов для обучения моделей кода. Этот метод позволяет генерировать качественные проверяемые данные кода и эффективно обучать модели вознаграждения для применения RL. Эти результаты открывают новые возможности для улучшения моделей генерации кода.
Как использовать ИИ для вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее ИИ-решение и внедряйте его постепенно.
- По итогам анализа результатов расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, свяжитесь с нами в нашем Телеграм-канале.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`




















