
«`html
LayerSkip: Решение ИИ для ускорения вывода больших языковых моделей (LLM)
Многие приложения используют большие языковые модели (LLM). Однако при развертывании на серверах с GPU их высокие требования к памяти и вычислениям приводят к значительным энергетическим и финансовым затратам.
Ускорение решений
Некоторые решения ускорения могут быть использованы с помощью ноутбучных GPU, но их точность может быть улучшена. Методы ускорения LLM направлены на уменьшение количества ненулевых весов, но разреженность — это количество бит, деленное на вес.
Практические решения и ценность
Исследователи из FAIR, GenAI и Reality Labs в Meta, Университета Торонто, Карнеги-Меллон Университета, Университета Висконсин-Мэдисон и Института рака Дана-Фарбер исследуют возможность уменьшения количества слоев для каждого токена через ранний выход вывода.
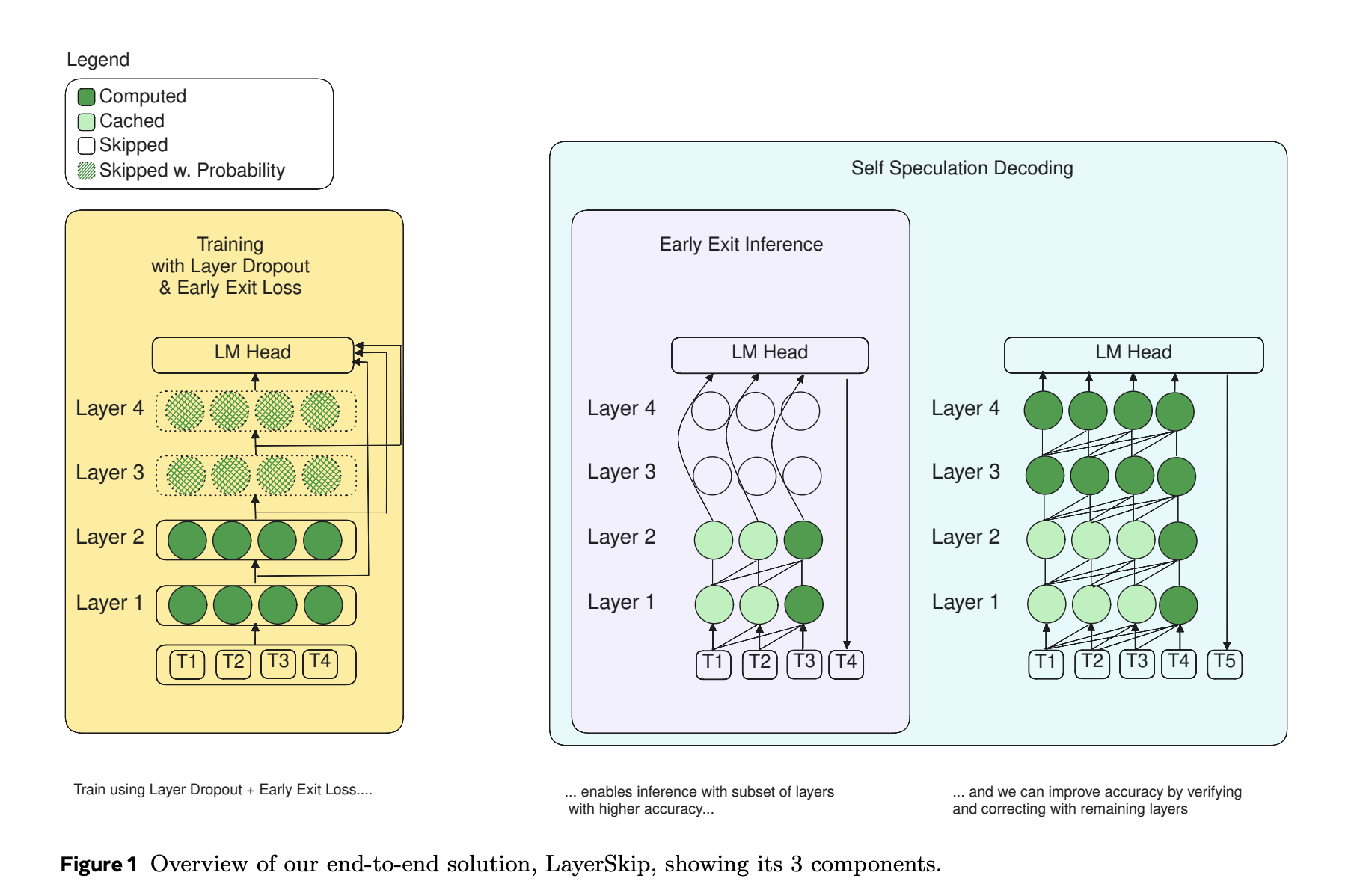
В отличие от квантизации или разреженности, ускорение путем уменьшения количества слоев не требует специального аппаратного обеспечения или программных ядер. Кроме того, спекулятивное декодирование — распространенная тенденция в ускорении LLM. Этот метод включает сопоставление огромной модели, называемой основной моделью, с более быстрой моделью, называемой черновой моделью, и не ущемляет точность. Однако сохранение кэша ключ-значение (KV) в двух отдельных моделях требует много работы. В данной работе представлен метод самоспекулятивного декодирования, новый подход, не требующий дополнительных моделей или вспомогательных слоев, объединяющий ранний выход с спекулятивным декодированием.
Исследователи используют примерный запрос для изучения того, что происходит на каждом уровне LLM для поддержки своего подхода. Они обучают модель Llama1 7B с использованием набора данных HumanEval и подают ей начальный запрос. Модель определяет и автоматически завершает тело функции, когда запрос содержит docstring и заголовок функции Python. Для генерации каждого токена итеративно применяется softmax к выходным вложениям каждого трансформаторного слоя LLM. Затем он проецируется на голову языковой модели (LM), состоящую из окончательной нормализации и линейных слоев модели. Наконец, исследователи находят индекс элемента вывода с наибольшим значением. На этом уровне предполагаемый токен связан с сгенерированным индексом. Некоторые источники называют этот процесс операцией размещения, поскольку он преобразует вложение в индекс.
Исследователи отмечают несколько моментов относительно предсказания токенов на каждом уровне. Во-первых, веса головы LM отличаются от весов вложения модели; поэтому предсказания токенов, сделанные на более ранних уровнях, бессмысленны. Проекции токенов сходятся к окончательному предсказанию в последующих уровнях. Во-вторых, использование каждого уровня для прогнозирования токена излишне. Среди 32 уровней в модели исследование показывает, что в среднем требуется 23,45 уровней для токена. Поэтому они могут получить только 26% сокращение вычислений, даже с идеальным предсказателем без дополнительной вычислительной нагрузки.
В результате модели LLM должны минимизировать вычисления, затраченные на колебания или «изменение своего мнения», и повысить точность прогнозирования с меньшим количеством слоев на токен. Вместо распределения вычислений по всем уровням моделей глубокого обучения должны быть более мотивированы прогнозировать свой окончательный вывод раньше. Команда показывает, что для прогнозирования «for» токенов, которые обычно кажутся простыми, требуется все 32 уровня.
Исследователи стремились сделать свою модель использовать более поздние уровни для сложных токенов и меньше полагаться на них для более простых. В идеальном мире предлагаемые модели должны зависеть меньше от более поздних уровней и больше от тех, которые предшествовали им. Для достижения этой цели команда использовала отсев слоев, практику исключения слоев во время обучения. Чтобы модель не была так сильно зависима от последующих уровней, команда использует более высокие коэффициенты отсева для этих слоев и более низкие для тех, которые предшествовали им.
Головы LLM LM обучаются удалять вложения из окончательного трансформаторного слоя. Они не получают инструкций о том, как удалять подповерхностные слои. По этой причине предлагаемый подход включает функцию потерь в процесс обучения, чтобы головы LM могли более эффективно «понимать» вложения предыдущих слоев.
Команда предлагает использовать общую голову LM через трансформаторные слои модели. Это упрощает развертывание и обслуживание, сокращает время обучения и уменьшает потребление памяти во время вывода и обучения.
Команда считает, что использование эвристик или предсказателей для раннего выхода во время вывода или изменение подхода к обучению для прогнозирования моделей раньше вероятно снизит точность. Они считают полезным проверить ранний прогноз перед запуском оставшихся слоев для его исправления. Они проверяют и исправляют предсказание раннего выхода с помощью техник спекулятивного декодирования. Проверка прогноза группы токенов быстрее, чем генерация каждого токена авторегрессивно, что является преимуществом спекулятивного декодирования. Поэтому они представляют метод самоспекулятивного декодирования, в котором каждый токен производится авторегрессивно с использованием раннего выхода. Затем оставшиеся слои используются для одновременной проверки и исправления группы токенов.
Некоторые исследования предлагают метод самоспекулятивного декодирования, который не требует изменений весов модели. Однако для этого решения, включающего донастройку или предварительное обучение модели, это необходимо. Скорость обучения должна быть увеличена, чтобы сохранить точность при начале с нуля с предварительной обучением отсева слоев. Однако поиск оптимальной скорости обучения может быть сложным и затратным по времени.
Исследователи предвидят, что это исследование побудит инженеров и исследователей включить предложенный отсев слоев и функцию потерь раннего выхода в свои рецепты предварительного обучения и донастройки. Отсев слоев, техника, которая может ускорить обучение при начале с нуля с предварительным обучением, обещает использоваться вместе с эффективными стратегиями, такими как LoRA, для донастройки, что потенциально улучшит производительность модели.
Команда хочет улучшить точность ранних выходных слоев для будущих улучшений в ускорении самоспекулятивного декодирования. Они надеются исследовать динамические условия для нахождения уникального выходного слоя для каждого токена, увеличивая процент принятия токенов для самоспекулятивного декодирования.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 40k+ ML SubReddit.
Исследование LayerSkip: An End-to-End AI Solution to Speed-Up Inference of Large Language Models (LLMs) представлено на MarkTechPost.
«`



















