
Реализация кода для использования Ollama через Google Colab
Введение
В этом руководстве мы создадим полностью функциональную систему, основанную на Retrieval-Augmented Generation (RAG), используя инструменты с открытым исходным кодом, которые работают без проблем в Google Colab. Мы рассмотрим, как настроить Ollama и использовать модели через Colab. Интеграция модели DeepSeek-R1 1.5B, модульной оркестрации LangChain и высокопроизводительного хранилища векторов ChromaDB позволяет пользователям запрашивать актуальную информацию из загруженных PDF-документов.
Настройка окружения
Для начала установим необходимые библиотеки и расширения:
!pip install colab-xterm
%load_ext colabxterm
Расширение colab-xterm позволяет получить доступ к терминалу прямо в среде Colab, что упрощает выполнение команд.
Установка и запуск Ollama
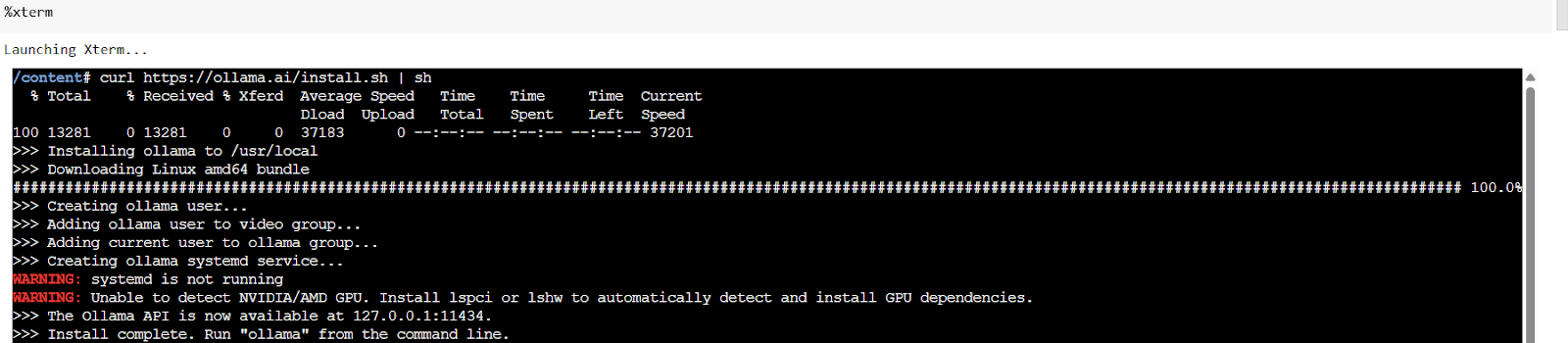
Установите Ollama и запустите его с помощью команды:
!curl -sSL https://ollama.com/install.sh | sh
ollama serve
Затем загрузите модель DeepSeek-R1:1.5B для построения RAG-пайплайна.
Установка библиотек для RAG-пайплайна
Установите основные библиотеки:
!pip install langchain langchain-community sentence-transformers chromadb faiss-cpu
Эти пакеты обеспечивают обработку документов, генерацию векторов и функции извлечения, необходимые для создания эффективной локальной системы RAG.
Загрузка и обработка PDF-документов
Импортируйте ключевые модули для работы с PDF:
from langchain_ent_loaders import PyPDFLoader
from langchain_rstores import Chroma
from langchain_dings import HuggingFaceEmbeddings
from langchain_ import Ollama
Затем загрузите PDF-документ:
uploaded = d()
file_path = list(())[0]
Проверьте тип загруженного файла и убедитесь, что это PDF.
Извлечение и обработка текста
Используйте библиотеку pypdf для извлечения содержимого:
loader = PyPDFLoader(file_path)
documents = ()
Затем разбейте документ на управляемые части:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text__documents(documents)
Создание векторного хранилища
Создайте векторное хранилище с помощью ChromaDB:
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = C_documents(documents=chunks, embedding=embeddings, persist_directory=persist_directory)
Создание RAG-пайплайна
Подключите модель DeepSeek-R1 к системе:
llm = OllamaLLM(model="deepseek-r1:1.5b")
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True)
Теперь вы можете задавать вопросы и получать ответы на основе загруженных документов.
Заключение
Это руководство демонстрирует, как создать легкую, но мощную систему RAG, которая эффективно работает на бесплатном уровне Google Colab. Решение позволяет пользователям задавать вопросы, основанные на актуальном содержании загруженных документов, с ответами, генерируемыми через локальную модель.
Автоматизация процессов с помощью ИИ
Изучите, какие процессы можно автоматизировать, и определите ключевые показатели эффективности (KPI) для оценки влияния ваших инвестиций в ИИ на бизнес. Начните с небольшого проекта, собирайте данные о его эффективности и постепенно расширяйте использование ИИ в вашей работе.
Контакты
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru.
Пример решения на основе ИИ
Посмотрите на практический пример решения на основе ИИ: бот для продаж, разработанный для автоматизации взаимодействия с клиентами на всех этапах их пути.






