
«`html
Large language models (LLMs) and the Challenge of Reasoning Tasks
Большие языковые модели (LLM) продемонстрировали значительные успехи в различных областях, но сталкиваются с серьезными трудностями в выполнении сложных задач рассуждения. Один из примеров — модель Mistral-7B, которая достигает лишь 36,5% точности на наборе данных GSM8K, несмотря на использование методик типа Chain-of-Thought (CoT).
Enhancing Reasoning Capabilities of Language Models
Исследователи разрабатывают различные методы для улучшения рассуждения языковых моделей. Это включает prompting-based методы, self-improvement методы, и новый метод Self-play muTuAl Reasoning (rStar), представленный исследователями из Microsoft Research Asia и Harvard University.
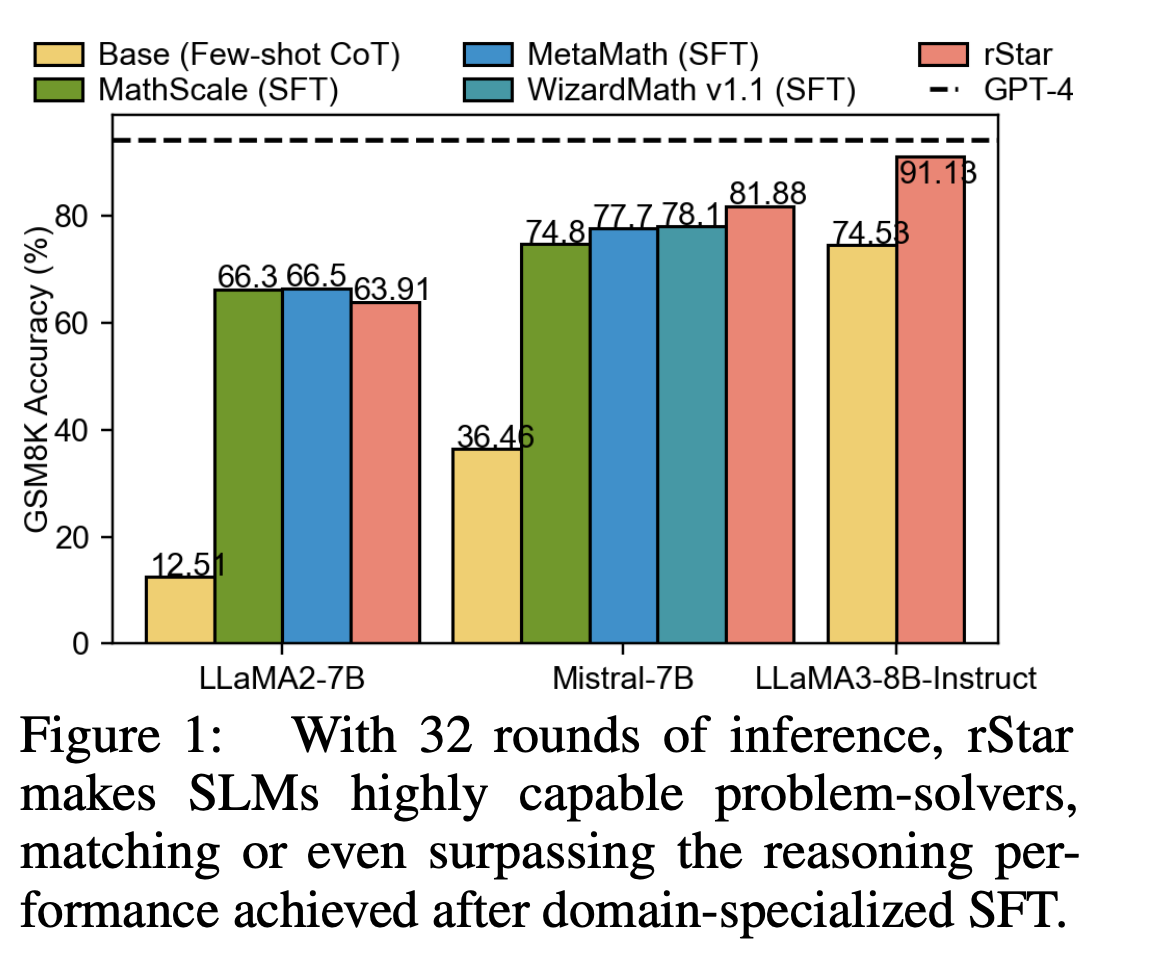
Self-play muTuAl Reasoning (rStar)
rStar — это уникальный подход, который направлен на улучшение способностей малых языковых моделей (SLM) к рассуждению во время вывода, без использования техники fine-tuning или более продвинутых моделей.
Возможности rStar
rStar использует метод само-игры, основанный на генерации и дискриминации, для улучшения способностей SLM к рассуждению. Он эффективно использует Monte Carlo Tree Search (MCTS) для генерации рассуждающих шагов и включает богатый набор человекоподобных действий рассуждения. Также rStar реализует тщательно разработанную функцию вознаграждения, оценивающую ценность каждого действия без использования техник самовознаграждения или внешнего контроля. Кроме того, он вводит дискриминацию с использованием второй SLM для проверки сгенерированных рассуждительных траекторий.
Результаты и Практическое Применение
rStar показал значительное улучшение результативности SLM на различных задачах рассуждения. Авторы выделяют результаты на разнообразных задачах рассуждения, повышение эффективности работы моделей на математических наборах данных и проведение сравнений с другими методами и моделями.
Развитие ИИ и Будущие Аспекты
Результаты исследования rStar подчеркивают его качественные и эффективные возможности по улучшению рассуждения SLM, благодаря чему повышается потенциал применения ИИ в различных областях..
Информация предоставлена в рамках исследования rStar.
Будущее уже здесь с решениями от AI Lab! Разверните ИИ постепенно с помощью AI Sales Bot и отслеживайте новости в Телеграм-канале и Twitter.
«`





























