


 за 6 месяцев.
А что бы вы сделали с этими деньгами?
за 6 месяцев.
А что бы вы сделали с этими деньгами? за 3 месяца. Какие процессы в вашем бизнесе скинуть роботу?
за 3 месяца. Какие процессы в вашем бизнесе скинуть роботу?  . Как это работает?
. Как это работает?  . Расскажите подробнее!
. Расскажите подробнее! 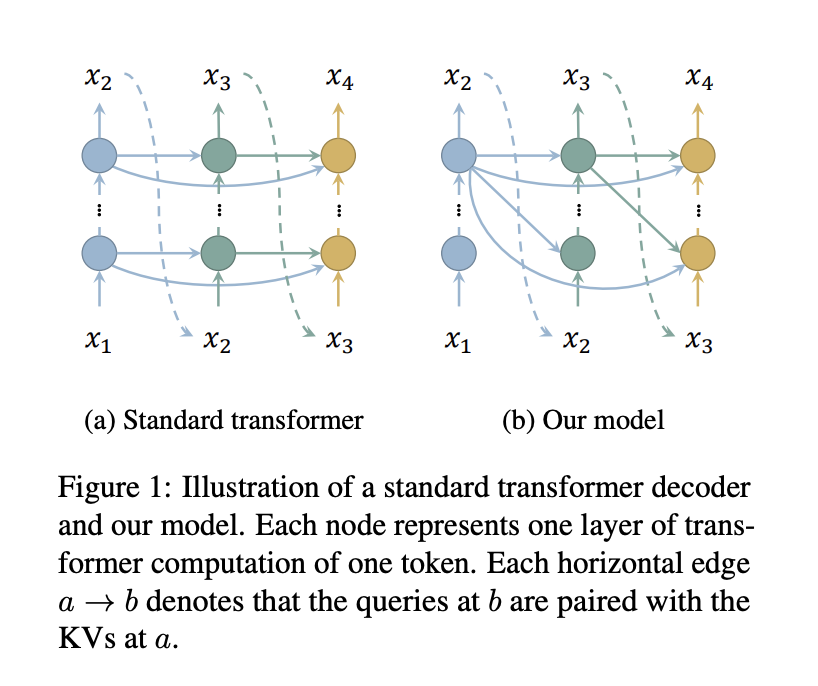
«`html
Эффективный подход к снижению потребления памяти и увеличению пропускной способности в LLM
Эффективное развертывание больших языковых моделей (LLM) требует высокой пропускной способности и низкой задержки. Однако значительное потребление памяти LLM, особенно кэшем ключ-значение (KV), мешает достижению больших объемов пакетов и высокой пропускной способности. Кэш ключ-значение, хранящий ключи и значения во время генерации, потребляет более 30% памяти GPU. Различные подходы, такие как сжатие последовательностей KV и динамические политики вытеснения кэша, направлены на смягчение этой нагрузки на память в LLM.
Практические решения:
- Внедрение страниц внимания для снижения фрагментации памяти.
- Сжатие запросов, удаление избыточности входного контекста и покадровое сжатие токенов.
- Обрезка неважных токенов, применение различных стратегий обрезки к кэшу внимания и хранение только важных токенов.
Исследователи из Школы информационных наук и технологий Университета ШанхайТэч и Шанхайского инженерного центра интеллектуального зрения и изображений представляют эффективный подход к снижению потребления памяти в кэше KV декодеров-трансформаторов путем уменьшения числа кэшируемых слоев. Путем сопоставления запросов всех слоев с ключами и значениями только верхнего слоя требуется кэшировать только ключи и значения одного слоя, что существенно экономит память без дополнительной вычислительной нагрузки.
Полученные результаты:
- Существенное сокращение потребления памяти и увеличение пропускной способности.
- Интеграция со StreamingLLM для снижения задержки и потребления памяти.
Проверьте статью и GitHub. Вся честь за это исследование принадлежит исследователям этого проекта.
Не забудьте подписаться на наш Twitter. Присоединяйтесь к нашим каналам в Telegram, Discord и LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка. Не забудьте присоединиться к нашему SubReddit.
«`


















