

 за 6 месяцев.
А что бы вы сделали с этими деньгами?
за 6 месяцев.
А что бы вы сделали с этими деньгами? за 3 месяца. Какие процессы в вашем бизнесе скинуть роботу?
за 3 месяца. Какие процессы в вашем бизнесе скинуть роботу?  . Как это работает?
. Как это работает?  . Расскажите подробнее!
. Расскажите подробнее! 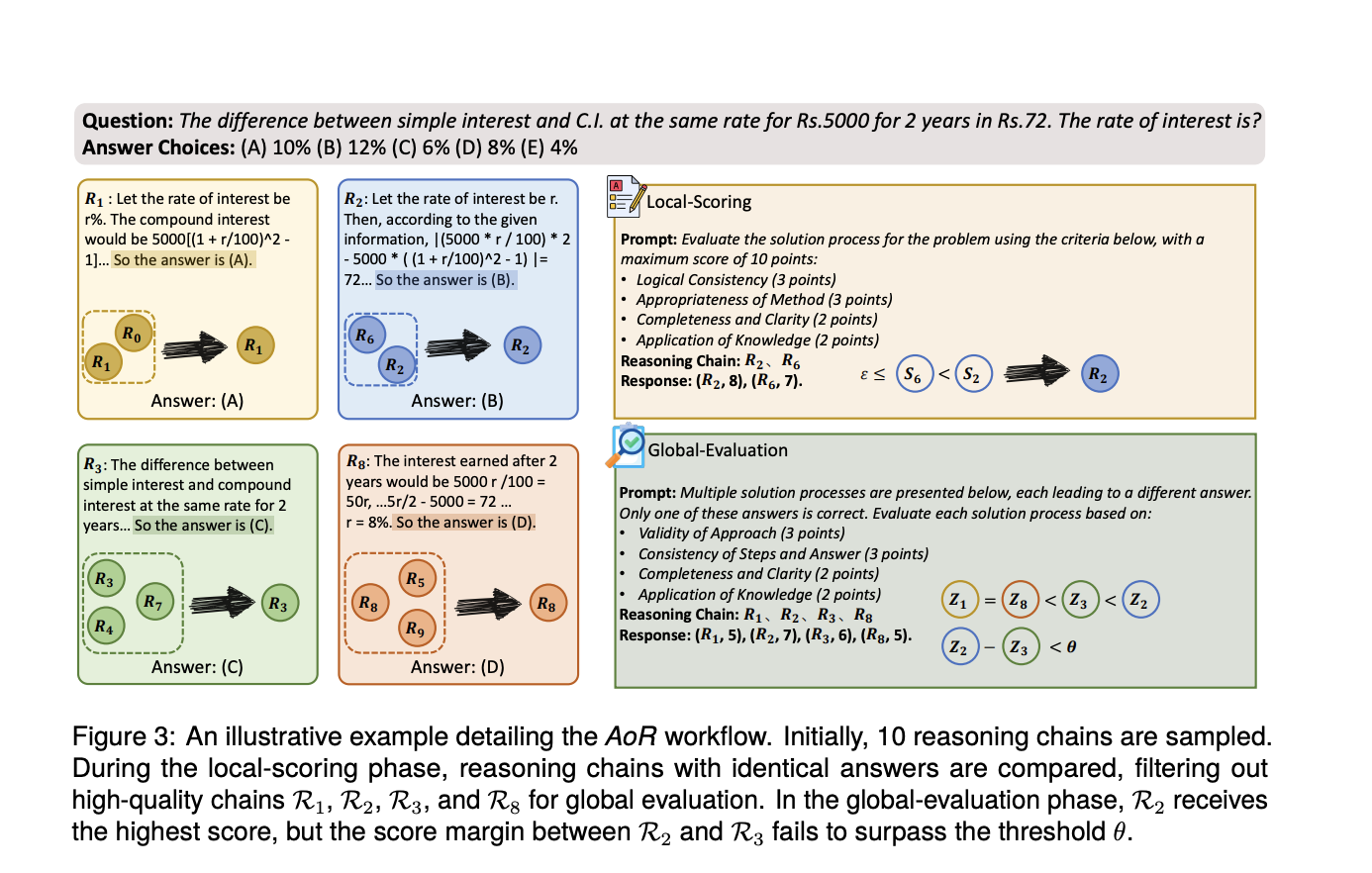
«`html
Революционные решения в области обработки естественного языка с использованием AI
Большие языковые модели (LLM) привели к значительным достижениям в различных задачах обработки естественного языка (NLP). Эти модели отлично справляются с пониманием и генерацией текста, играя ключевую роль в таких приложениях, как машинный перевод, резюмирование и более сложные задачи рассуждения. Прогресс в этой области продолжает изменять способы взаимодействия машин с языком, открывая новые пути для исследований и разработок.
Преодоление проблем в области обработки естественного языка
Одно из значительных препятствий в этой области – разрыв между способностями рассуждения LLM и экспертностью на уровне человека. Эта несбалансированность особенно заметна в сложных задачах рассуждения, где традиционным моделям не хватает сил для продуцирования точных результатов. Проблема заключается в том, что модели полагаются на механизмы мажоритарного голосования, которые часто не справляются, когда неправильные ответы доминируют в наборе сгенерированных реакций.
Новые методы улучшения рассуждений LLM
Существующие работы включают в себя механизм CoT (Chain-of-Thought), который улучшает рассуждения путем генерации промежуточных шагов. Самосогласованность использует несколько цепочек рассуждений и выбирает наиболее часто встречающийся ответ. Подход на основе сложности фильтрует цепочки рассуждений по сложности. DiVeRSe обучает верификаторы оценивать цепочки, а Progressive-Hint Prompting использует предыдущие ответы в качестве подсказок. Эти методы направлены на улучшение способностей LLM к рассуждению путем улучшения последовательности и точности сгенерированных ответов.
Инновационный фреймворк AoR для оценки рассуждающих цепочек
Исследователи из университетов Фудан, Национального университета Сингапура и Midea AI Research Center представили иерархический фреймворк обобщенного рассуждения под названием AoR (Aggregation of Reasoning). Этот инновационный фреймворк сдвигает акцент с частоты ответов на оценку цепочек рассуждений. AoR включает динамическое выборочное исследование, которое регулирует количество цепочек рассуждений в зависимости от сложности задачи, тем самым улучшая точность и надежность рассуждений LLM.
Продолжение на MarkTechPost
«`




































