Улучшение рассуждений LLM с помощью многопопытного обучения с подкреплением
Недавние достижения в области обучения с подкреплением (RL) для больших языковых моделей (LLM), такие как DeepSeek R1, показали, что даже простые задачи вопрос-ответ могут значительно улучшить способности к рассуждению. Традиционные подходы RL обычно основываются на одноразовых задачах, где модель получает вознаграждение на основе правильности одного ответа. Однако эти методы страдают от недостатка вознаграждений и не обучают модели уточнять свои ответы на основе отзывов пользователей.
Преимущества многопопытного подхода
Чтобы решить эти ограничения, были исследованы многопопытные подходы RL, позволяющие LLM делать несколько попыток решения задачи, тем самым улучшая свои способности к рассуждению и самокоррекции. Некоторые исследования рассматривают механизмы планирования и самокоррекции в RL для LLM, вдохновляясь алгоритмом Thinker, который позволяет агентам исследовать альтернативы перед тем, как принять решение.
Метод DeepSeek R1
Предложенный метод расширяет задачу вопрос-ответ DeepSeek R1 в многопопытную структуру, используя исторические ошибки для уточнения ответов и повышения уровня рассуждений. Исследователи DualityRL и Шанхайской лаборатории ИИ представляют многопопытный подход RL, позволяющий моделям уточнять ответы через несколько попыток с обратной связью.
Экспериментальные результаты
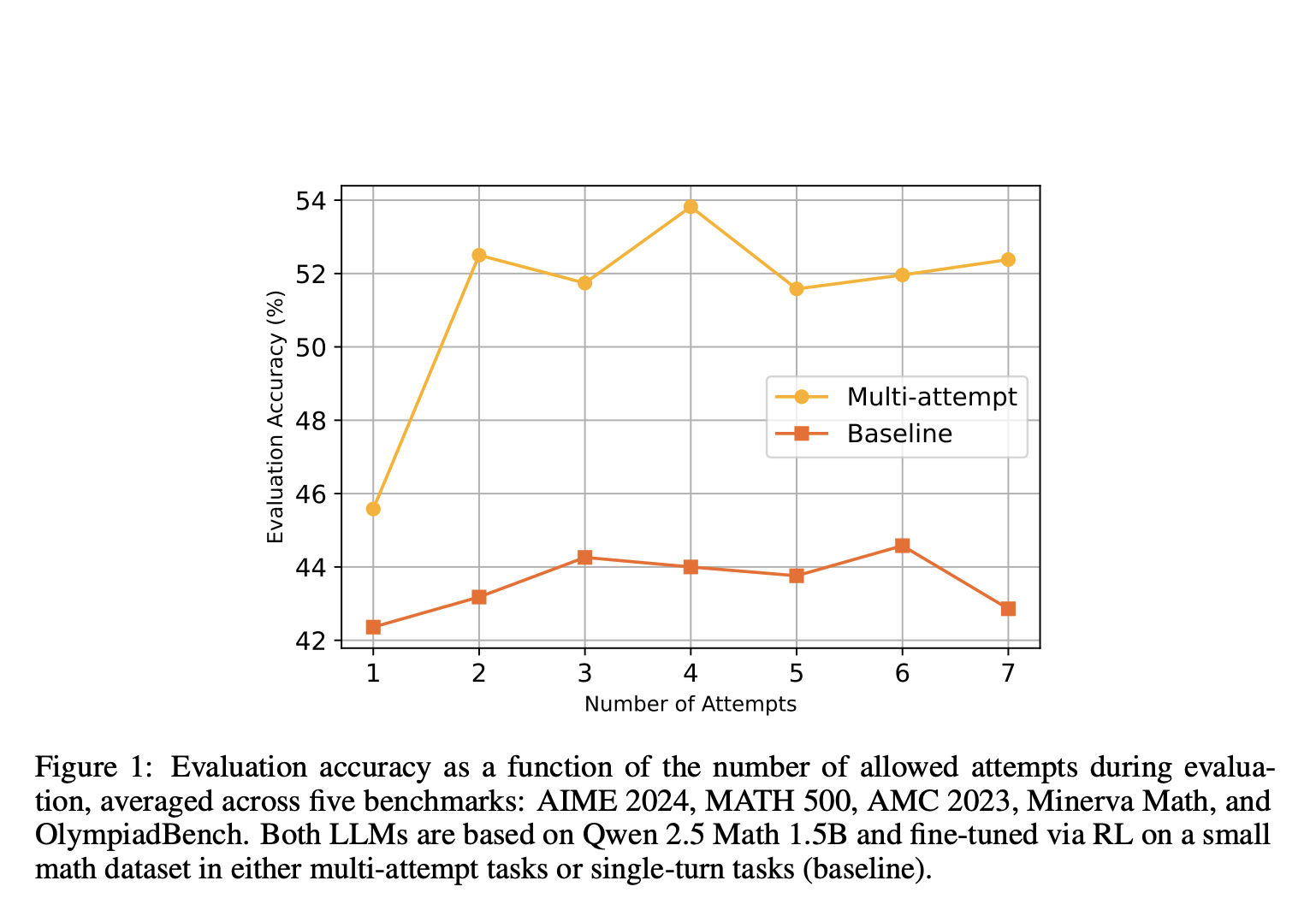
Экспериментальные результаты показывают увеличение точности на 45.6% до 52.5% с двумя попытками на математических тестах, в то время как модели с одноразовыми задачами показывают лишь незначительное улучшение. Модель обучается самокоррекции с использованием метода Proximal Policy Optimization (PPO), что приводит к возникновению способностей к рассуждению.
Метод многопопытной задачи
В многопопытном подходе вводится фиксированное количество попыток, где модель получает вознаграждение за правильные ответы и штрафы за неправильные, но хорошо оформленные ответы. Этот метод способствует исследованию в ранних попытках, не накладывая штрафы, и использует PPO для оптимизации.
Выводы и рекомендации
Исследование показывает, что многопопытный подход значительно улучшает способности моделей к уточнению ответов на основе обратной связи. Хотя прирост производительности на математических тестах скромен, подход улучшает эффективность поиска и самокоррекцию. Будущие работы могут дополнительно исследовать внедрение детализированной обратной связи или вспомогательных задач для повышения возможностей LLM.
Практические бизнес-решения
Изучите, как технологии искусственного интеллекта могут изменить ваш подход к работе:
- Автоматизируйте процессы: Найдите моменты в взаимодействии с клиентами, где ИИ может добавить наибольшую ценность.
- Определите ключевые показатели: Убедитесь, что ваши инвестиции в ИИ действительно положительно влияют на бизнес.
- Выберите подходящие инструменты: Подберите решения, которые отвечают вашим потребностям и позволяют их настраивать.
- Начните с небольшого проекта: Соберите данные о его эффективности и постепенно расширяйте использование ИИ в вашей работе.
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram https://t.me/itinai.
Посмотрите практический пример решения на базе ИИ: бот продаж с https://itinai.ru/aisales, разработанный для автоматизации общения с клиентами круглосуточно и управления взаимодействиями на всех этапах пути клиента.





