
«`html
Новые возможности в области обучения усиленным обучением и робототехники с использованием больших моделей обработки зрительной и языковой информации (VLM и LLM)
Недавние достижения в использовании больших моделей обработки зрительной и языковой информации (VLM и LLM) значительно повлияли на усиленное обучение (RL) и робототехнику. Эти модели продемонстрировали свою полезность в обучении политик роботов, высокоуровневом рассуждении и автоматизации создания функций вознаграждения для обучения политик. Этот прогресс значительно сократил необходимость в специфических знаниях, обычно требуемых от исследователей в области усиленного обучения.
Автоматизация усиленного обучения и робототехники с использованием моделей обработки зрительной и языковой информации
В области автоматизации научных и инженерных задач агенты, оснащенные LLM, разрабатываются для помощи в задачах программирования в паре, а также для полного цикла разработки программного обеспечения. Агенты на основе LLM также используются в научных исследованиях для генерации направлений исследований, анализа литературы, автоматизации научных открытий и проведения экспериментов по машинному обучению. В области робототехники агенты на основе LLM используются для написания кода политики, декомпозиции высокоуровневых задач на подзадачи и даже предложения задач для открытого исследования. Отличными примерами являются агент Voyager для Minecraft и системы CaP и SayCan для задач робототехники. Эти подходы демонстрируют потенциал LLM в автоматизации сложных процессов рассуждения и принятия решений в физических средах. Однако большинство существующих работ сосредоточены на автоматизации отдельных этапов или конкретных областей. Остается вызов в разработке интегрированных систем, способных автоматизировать всю экспериментальную рабочую процедуру, особенно в усиленном обучении для робототехники, где предложение задач, декомпозиция, выполнение и оценка должны быть бесшовно объединены.
Инновационная архитектура агента для автоматизации ключевых аспектов рабочего процесса усиленного обучения
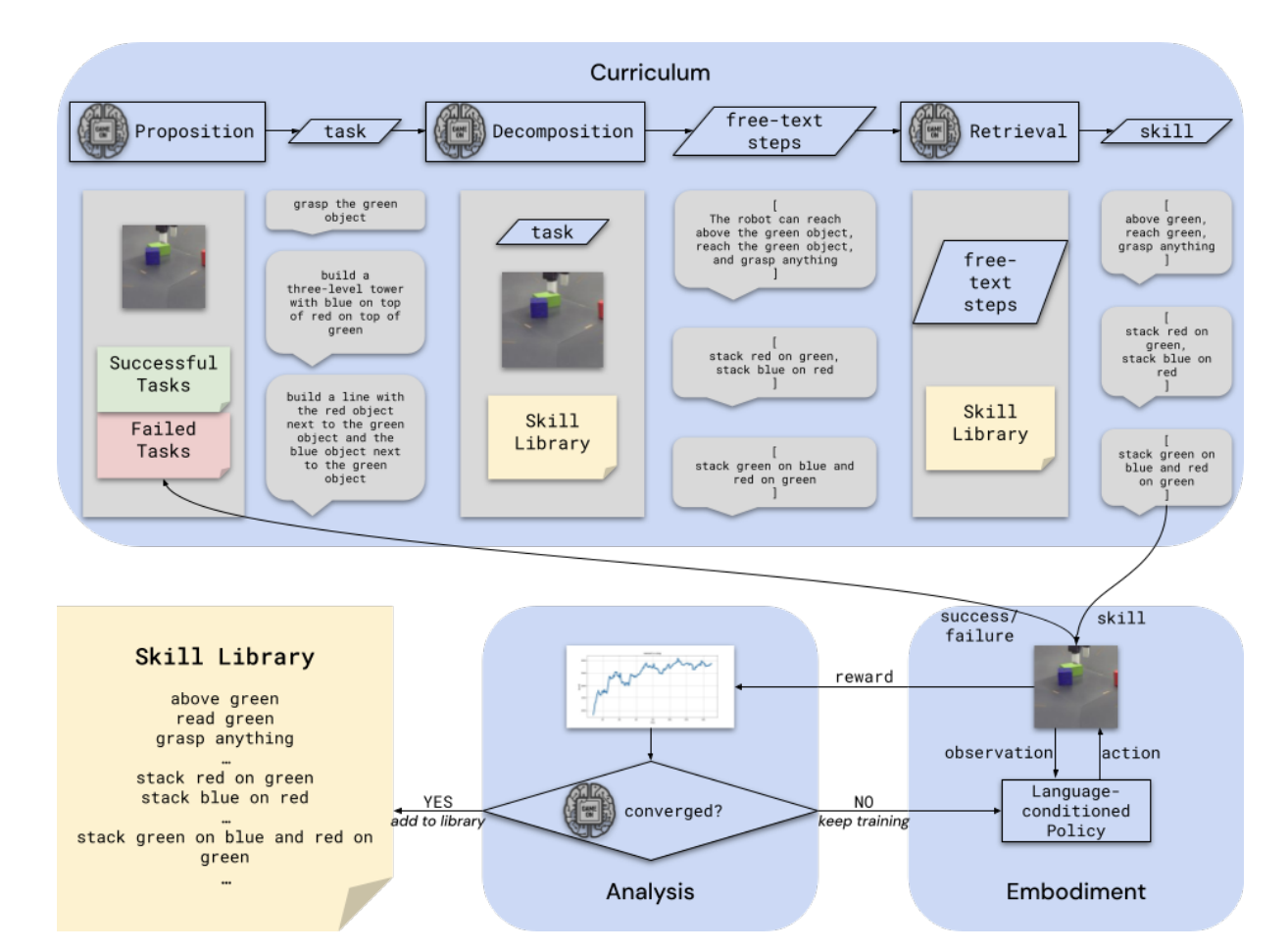
Исследователи DeepMind предлагают инновационную архитектуру агента, которая автоматизирует ключевые аспекты рабочего процесса усиленного обучения, с целью обеспечить автоматизированное овладение контрольными областями для агентов в физических средах. Эта система использует VLM для выполнения задач, обычно выполняемых человеческими экспериментаторами, включая:
- Мониторинг и анализ прогресса эксперимента
- Предложение новых задач на основе прошлых успехов и неудач агента
- Декомпозиция задач на последовательности подзадач (навыков)
- Выбор соответствующих навыков для выполнения
Этот подход позволяет системе создавать автоматизированные учебные планы, представляя одно из первых предложений для системы, которая использует VLM на протяжении всего цикла эксперимента по усиленному обучению.
Применение в симулированной задаче робототехники
Для проверки своей предложенной системы исследователи реализовали ее компоненты и применили их к симулированной задаче робототехники по управлению манипуляцией. Архитектура системы состоит из нескольких взаимодействующих модулей:
- Модуль учебного плана: извлекает изображения из окружения и включает их в предложения целей. Декомпозирует цели на шаги и извлекает подписи навыков. Если все шаги могут быть сопоставлены известным навыкам, последовательность навыков отправляется в модуль воплощения.
- Модуль воплощения: использует обученную политику, зависящую от текста (алгоритм Perceiver-Actor-Critic) для выполнения последовательностей навыков. Несколько экземпляров этого модуля могут одновременно выполнять эпизоды.
- Модуль анализа: используется вне цикла эксперимента для оценки точек сходимости.
Модули взаимодействуют через чат-интерфейс в сессии Google Meet, обеспечивая легкое подключение и человеческую интроспекцию. Модуль учебного плана контролирует поток программы, изменяя навыки через фиксированные интервалы во время выполнения.
Для обучения политики система использует модель Perceiver-Actor-Critic (PAC), которая может быть обучена с использованием офлайн усиленного обучения и зависит от текста. Это позволяет использовать данные неэкспертного исследования и переоценку данных с несколькими функциями вознаграждения. Высокоуровневая система использует стандартную модель Gemini 1.5 Pro с запросами, разработанными с использованием библиотеки OneTwo Python. Запросы включают небольшое количество ручных образцов с изображениями из предыдущих экспериментов, охватывающих задачи предложения, декомпозиции, извлечения и анализа. Эта реализация демонстрирует практический подход к интеграции VLM в рабочий процесс усиленного обучения, обеспечивая автоматизированное предложение задач, декомпозицию и выполнение в симулированной робототехнической среде.
Исследователи оценили свой подход, используя задачу стекирования блоков с участием 7-DoF робота Franka Panda в симуляторе MuJoCo. Сначала они обучили модель PAC с 140 миллионами параметров на базовых навыках, используя существующий набор данных из 1 миллиона эпизодов. Затем процесс сбора данных, основанный на Gemini, сгенерировал 25 тысяч новых эпизодов, исследуя различные температуры выборки VLM и наборы навыков. Модуль анализа использовался для определения оптимальных точек досрочной остановки и оценки сходимости навыков. Способность модуля учебного плана работать с растущим набором навыков была изучена на различных этапах эксперимента, демонстрируя способность системы к постепенному обучению и декомпозиции задач.
Инновационная архитектура агента для усиленного обучения
Предложенная исследователями инновационная архитектура агента для усиленного обучения, использующая VLM для автоматизации задач, обычно выполняемых человеческими экспериментаторами, направлена на обеспечение возможности автономного приобретения и овладения агентами расширяющимся набором навыков. Прототипная реализация продемонстрировала несколько ключевых возможностей:
- Предложение новых задач для исследования
- Декомпозиция задач на последовательности навыков
- Анализ прогресса обучения
Несмотря на некоторые упрощения в прототипе, система успешно собрала разнообразные данные для самосовершенствования политики управления и изучила новые навыки за пределами своего первоначального набора. Учебный план продемонстрировал адаптивность в предложении задач на основе доступной сложности навыков.
Подробнее ознакомьтесь с исследованием. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram каналу и группе в LinkedIn.
Не забудьте присоединиться к нашему SubReddit по машинному обучению с более чем 50 тысячами подписчиков.
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ: «SAM 2 для видео: как настроить на ваши данные» (Ср, 25 сентября, 4:00 — 4:45 EST)
Эта статья была опубликована на сайте MarkTechPost.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Automating Reinforcement Learning Workflows with Vision-Language Models: Towards Autonomous Mastery of Robotic Tasks.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!