
«`html
Улучшение обучения агентов с помощью DIAMOND в сфере искусственного интеллекта
Обучение с подкреплением (RL) основано на том, что агенты учатся принимать решения взаимодействуя с окружающей средой. RL достиг впечатляющих результатов в играх, робототехнике и автономных системах. Цель — разработать алгоритмы, позволяющие агентам эффективно выполнять задачи, максимизируя накопленные вознаграждения через пробно-ошибочное взаимодействие. Путем непрерывной адаптации к новым данным эти алгоритмы помогают улучшать производительность со временем, делая RL важным компонентом в разработке интеллектуальных систем.
Проблема эффективности выборки
Одной из значительных проблем в RL является неэффективность выборки, когда агентам требуется обширное взаимодействие с окружающей средой для изучения эффективных стратегий. Это ограничение затрудняет практическое применение RL в реальных сценариях, особенно в средах, где получение выборок затратно или занимает много времени.
Практические решения
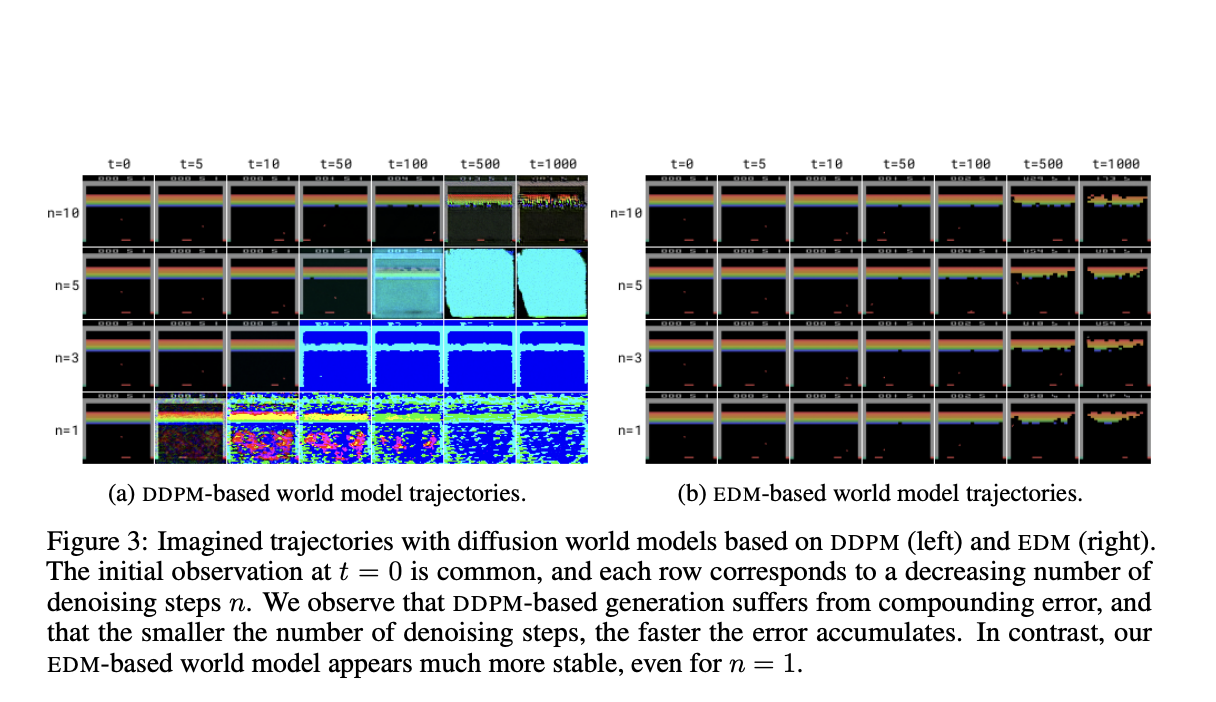
Существующие исследования включают в себя мировые модели, такие как SimPLe и Dreamer, которые обучают агентов RL в симулированных средах. DIAMOND (DIffusion As a Model Of eNvironment Dreams) представляет собой новый RL агент, обученный с использованием мировой модели на основе диффузии. DIAMOND использует преимущества моделей диффузии, что делает его более эффективным в обучении и способным адаптироваться в сложных средах.
Оценка производительности
Производительность DIAMOND оценивается на бенчмарке Atari 100k, где он достигает среднего нормализованного человека показателя 1.46, устанавливая новый стандарт для агентов, обученных полностью в мировой модели.
В заключение, DIAMOND представляет значительный прогресс в RL, решая проблему неэффективности выборки через улучшенное мировое моделирование. Интеграция моделей диффузии в мировое моделирование является шагом вперед в разработке более надежных и эффективных систем RL, что открывает путь для более широких применений и улучшенной производительности ИИ.
Подробнее ознакомьтесь с статьей и GitHub.
«`





















