
«`html
Алгоритм машинного обучения TD3-BST: динамическая настройка силы регуляризации с использованием модели неопределенности
Обучение с подкреплением (RL) — это подход к обучению, при котором агент взаимодействует с окружающей средой, собирая опыт, и стремится максимизировать вознаграждение, получаемое из среды. Оффлайн алгоритмы RL используются для изучения эффективных и применимых политик с помощью статических наборов данных. Однако они требуют значительной настройки гиперпараметров для каждого набора данных, что может затруднить их применение в практических областях.
Алгоритм TD3-BST
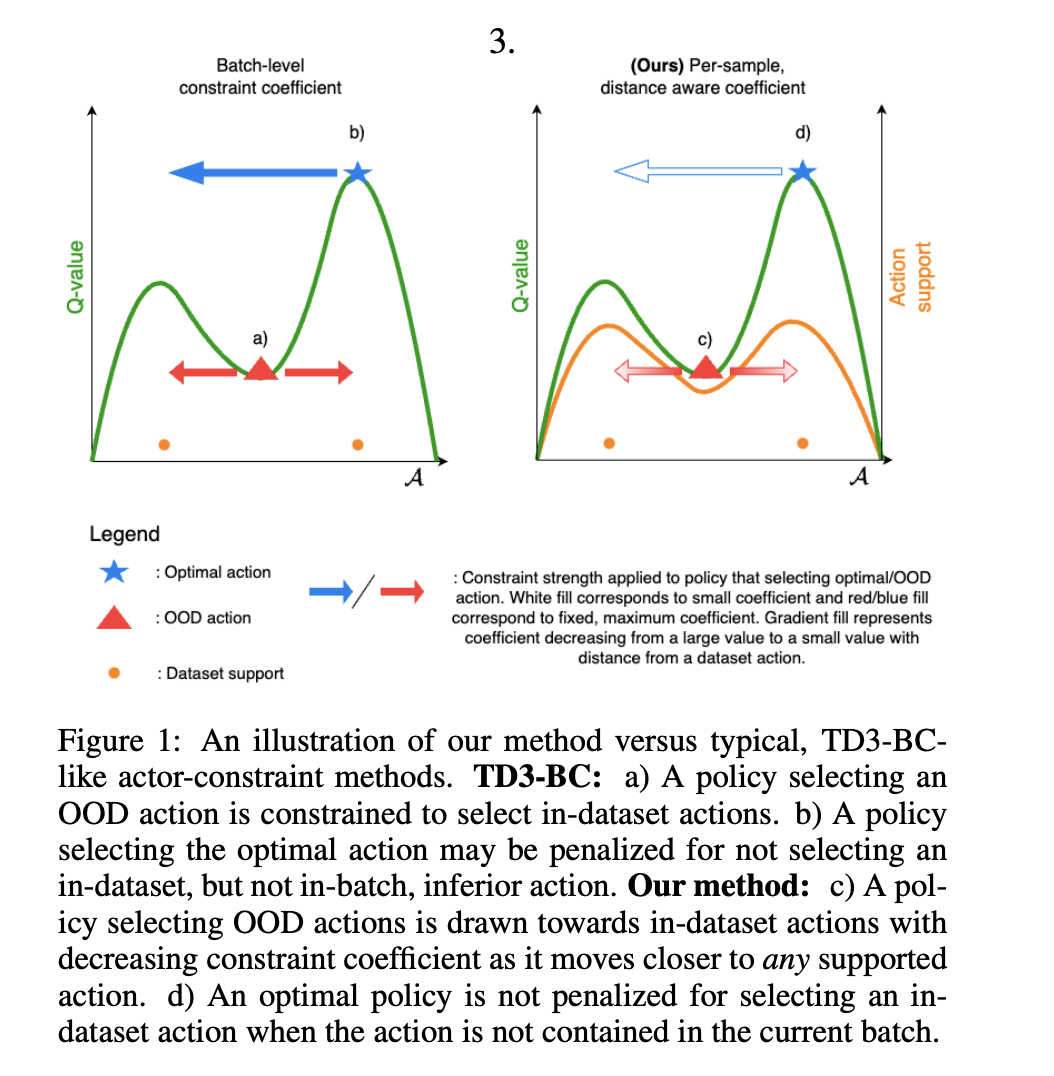
Исследователи из Имперского колледжа Лондона представили алгоритм TD3-BST, который использует модель неопределенности для динамической настройки силы регуляризации. TD3-BST помогает оптимизировать Q-значения вокруг мод набора данных и продемонстрировал передовую производительность при тестировании на наборах данных D4RL.
Применение в бизнесе
Если вы хотите использовать искусственный интеллект для развития своей компании, обратите внимание на TD3-BST. Определите области, где можно применить автоматизацию и оптимизацию с помощью ИИ, выберите подходящее решение и внедряйте его постепенно, начиная с малых проектов. Если вам нужны советы по внедрению ИИ, обращайтесь к нам.
Подробнее ознакомьтесь с статьей. Все заслуги за это исследование принадлежат его авторам.
Не забудьте следить за нами в Twitter и присоединиться к нашим каналам в Telegram и LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
AI Sales Bot
Попробуйте AI Sales Bot, который поможет вам в продажах, отвечая на вопросы клиентов, генерируя контент и снижая нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
«`





















