
Оценка уязвимостей методов отказа от знаний в больших языковых моделях: Комплексный анализ в белом ящике
Практические решения для безопасного развития и применения больших языковых моделей
Большие языковые модели (LLM) приобрели огромные возможности благодаря обучению на обширных интернет-данных. Однако такая широкая экспозиция неизбежно включила вредоносный контент, позволяя LLM генерировать токсичный, незаконный, предвзятый и нарушающий конфиденциальность материал. Для обеспечения ответственного развития и применения LLM в различных областях требуются более эффективные решения.
Исследователи предприняли различные подходы для решения вызовов, создаваемых вредоносными знаниями в LLM. Методы обучения безопасности, такие как DPO и PPO, применяются для настройки моделей на отказ в ответах на вопросы о опасной информации. Однако эти меры безопасности показали ограниченную надежность, поскольку проблемы обхода продолжают возникать.
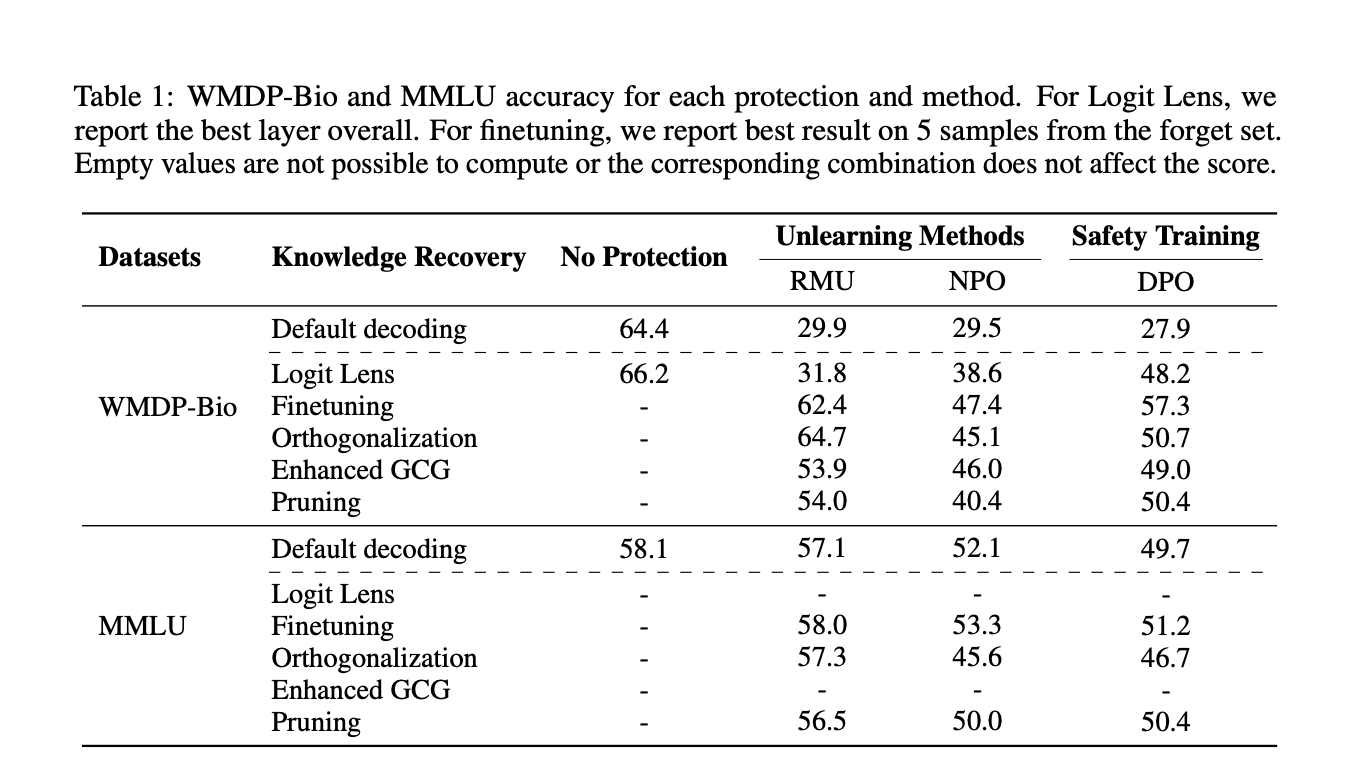
Отказ от знаний выделяется как многообещающее решение, направленное на обновление весов модели для полного удаления определенных знаний. Однако недавние адверсарные оценки показали уязвимости в методах отказа от знаний, подчеркивая необходимость более надежных методов и тщательных протоколов оценки.
Исследование фокусируется на методах отказа от знаний для обеспечения безопасности, сосредотачиваясь на удалении опасных знаний из больших языковых моделей. Результаты показывают значительные уязвимости в методах отказа от знаний, что подчеркивает необходимость развития более надежных техник и протоколов оценки.
Для получения дополнительной информации и консультаций по внедрению ИИ обращайтесь к нам на itinai. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot itinai.ru/aisales — инструмент для автоматизации работы с клиентами и снижения нагрузки на персонал.
Узнайте, как решения от AI Lab itinai.ru могут изменить ваши процессы и повысить эффективность вашего бизнеса!

















