Возвращение к Weight Decay: За пределами Регуляризации в Современном Глубоком Обучении
Практические Решения и Ценность
Весовое уменьшение (Weight decay) и ℓ2-регуляризация имеют важное значение в машинном обучении, особенно в ограничении емкости сетей и уменьшении ненужных компонентов веса. Эти техники соответствуют принципам бритвы Оккама и являются ключевыми в обсуждениях о границах обобщения.
Недавние исследования подвергли сомнению корреляцию между нормативными мерами и обобщением в глубоких сетях. Весовое уменьшение широко используется в современных глубоких сетях, таких как GPT-3, CLIP и PALM, но его эффект до сих пор не полностью понятен. Появление новых архитектур, таких как трансформеры и моделирование языка практически за одну эпоху, дополнительно усложнило применимость классических результатов в современных настройках глубинного обучения.
Усилия по пониманию и использованию весового уменьшения значительно продвинулись со временем. Недавние исследования выделяют различные эффекты весового уменьшения и ℓ2-регуляризации, особенно для оптимизаторов, таких как Adam. Они также подчеркивают влияние весового уменьшения на динамику оптимизации, включая его воздействие на эффективные темпы обучения в сетях с инвариантностью к масштабу.
Другие методы включают его роль в регуляризации якобиана входных данных и создание специфических затухающих эффектов в некоторых оптимизаторах. Более того, недавнее исследование содержит связь между весовым уменьшением, длительностью обучения и обобщающей способностью. Хотя весовое уменьшение показано, что улучшает точность тестирования, улучшения часто умеренны, что указывает на значительную роль неявной регуляризации в глубоком обучении.
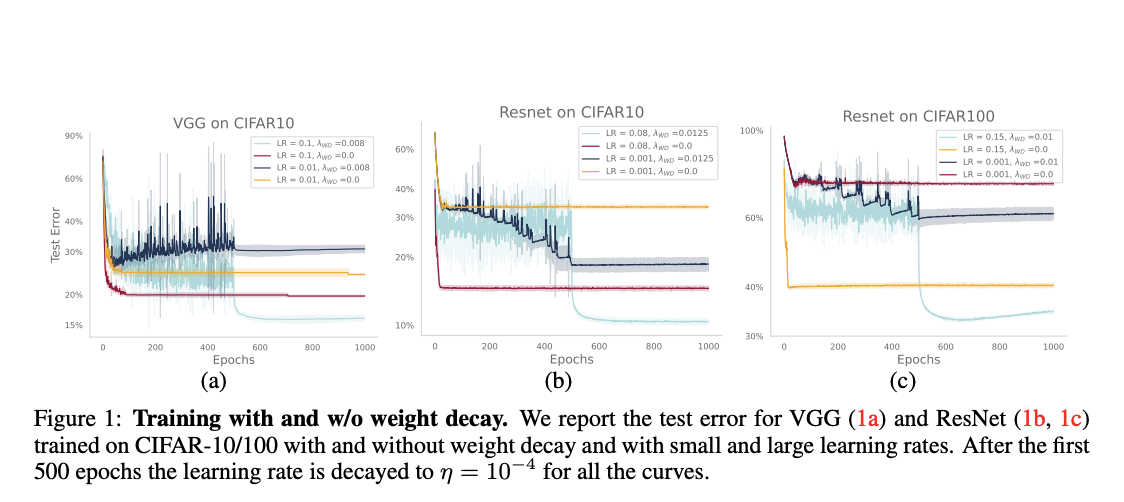
Исследователи из Лаборатории теории машинного обучения EPFL предложили новую перспективу на роль весового уменьшения в современном глубоком обучении. Их работа вызывает сомнения в традиционное представление о весовом уменьшении прежде всего как о методе регуляризации, изученном в классической теории обучения. Они показали, что весовое уменьшение значительно изменяет динамику оптимизации в перепараметризованных и недопараметризованных сетях. Кроме того, весовое уменьшение предотвращает внезапные потери расхождений при обучении смешанным представлением с плавающей запятой bfloat16, что является ключевым аспектом обучения LLM.
Эксперименты проводятся путем обучения моделей GPT-2 на OpenWebText с использованием репозитория NanoGPT. Модель с 124 миллионами параметров (GPT-2-Small), обученная за 50 000 итераций, используется с модификациями для обеспечения практичности в рамках академических ограничений.
Проверьте Paper и GitHub. Все заслуги за это исследование принадлежат исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш newsletter.





















