
«`html
Решения AI для улучшения производительности и доверия пользователей
Несоответствие между ожиданиями людей от возможностей и реальной производительностью систем искусственного интеллекта мешает эффективному использованию больших языковых моделей (LLM). Неверные предположения об их возможностях могут привести к опасным ситуациям, особенно в критических приложениях, таких как самоуправляемые автомобили или медицинская диагностика. Ученые Массачусетского технологического института (MIT) совместно с Гарвардским университетом рассматривают вызов оценки больших языковых моделей (LLM) из-за их широкой применимости в различных задачах, от составления электронных писем до помощи в медицинской диагностике.
Оценка соответствия LLM ожиданиям людей
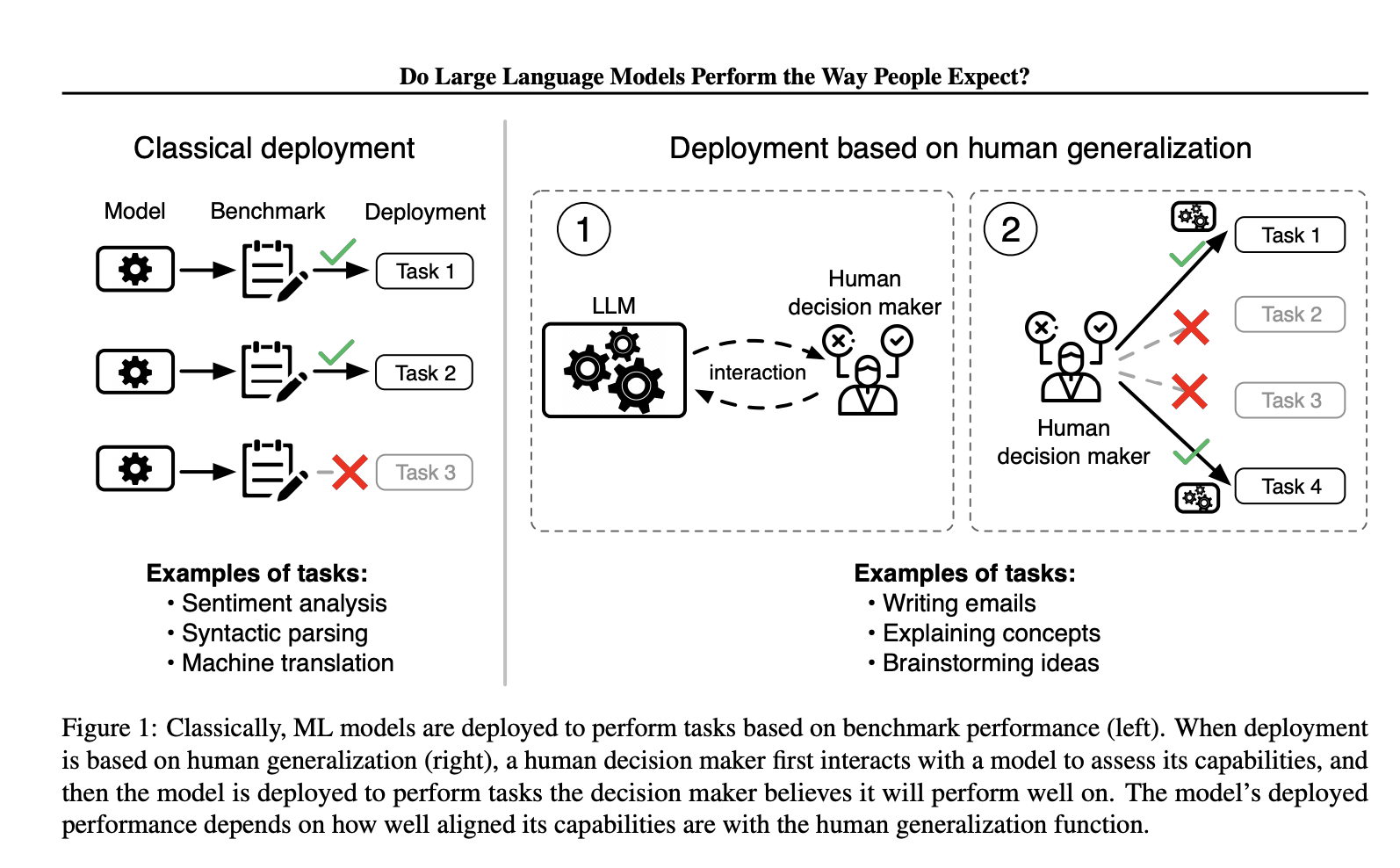
Текущие методы оценки LLM включают бенчмаркинг их производительности на широком спектре задач, но они недостаточно учитывают человеческий аспект при принятии решений о внедрении. Ученые предлагают новую концепцию оценки LLM на основе их соответствия человеческим представлениям о возможностях. Они вводят понятие функции обобщения человека, которая моделирует, как люди корректируют свои представления о возможностях LLM после взаимодействия с ними. Этот подход направлен на понимание и измерение соответствия между ожиданиями людей и производительностью LLM, с признанием того, что несоответствие может привести к чрезмерной уверенности или недостаточной уверенности в внедрении этих моделей.
Интеграция человеческих факторов в разработку и оценку LLM
Функция обобщения человека разработана для наблюдения за тем, как люди формируют представления о возможностях LLM на основе их ответов на конкретные вопросы. Ученые разработали опрос для измерения этого обобщения, показывая участникам вопросы, на которые человек или LLM правильно или неправильно ответили, а затем спрашивая, считают ли они, что человек или LLM ответят правильно на связанный вопрос. Этот опрос сгенерировал набор данных из почти 19 000 примеров по 79 задачам, подчеркивая, как люди обобщают о производительности LLM. Результаты показали, что люди лучше обобщают о производительности других людей, чем о производительности LLM. Заметно, что более простые модели иногда превосходили более сложные, такие как GPT-4, в ситуациях, где люди больше доверяли неправильным ответам.
Итоги и рекомендации
Данное исследование фокусируется на несоответствии между ожиданиями людей и возможностями LLM, которое может привести к неудачам в критических ситуациях. Функция обобщения человека предоставляет новую концепцию для оценки этого соответствия. Оно подчеркивает необходимость лучшего понимания и интеграции человеческого обобщения в разработку и оценку LLM. Предлагаемая концепция учитывает человеческие факторы при внедрении универсальных LLM для улучшения их производительности в реальном мире и доверия пользователей.
Подробнее см. Статью и детали. Вся честь за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему телеграм-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш рассылка.
Не забудьте присоединиться к нашему 47k+ ML SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Источник: MarkTechPost.
«`





















