
«`html
Большие языковые модели и их вызовы
Большие языковые модели (LLM) показывают отличные результаты в различных задачах, но сталкиваются с проблемами многоступенчатого мышления. Это особенно заметно при решении сложных задач, таких как математические задачи и управление агентами. Традиционные методы обучения с подкреплением, такие как PPO, часто требуют больших вычислительных ресурсов и данных, что делает их менее практичными.
Представляем OREO: Оптимизация оффлайн-результатов
OREO (Offline REasoning Optimization) — это подход оффлайн обучения с подкреплением, разработанный для устранения недостатков существующих методов улучшения многоступенчатого мышления LLM. OREO использует оптимизацию мягкого уравнения Беллмана и позволяет работать с непарными наборами данных. Это способствует более точному распределению «кредита» за успехи по разным этапам логического вывода.
Технические детали и преимущества
Ключевая инновация OREO заключается в оптимизации мягкого уравнения Беллмана для одновременного обучения моделей политики и ценности. Эта стратегия обеспечивает точное распределение «кредита» и предлагает гибкость в подходах к решению задач. OREO также использует передовые методы поиска во время тестирования, что повышает точность результатов.
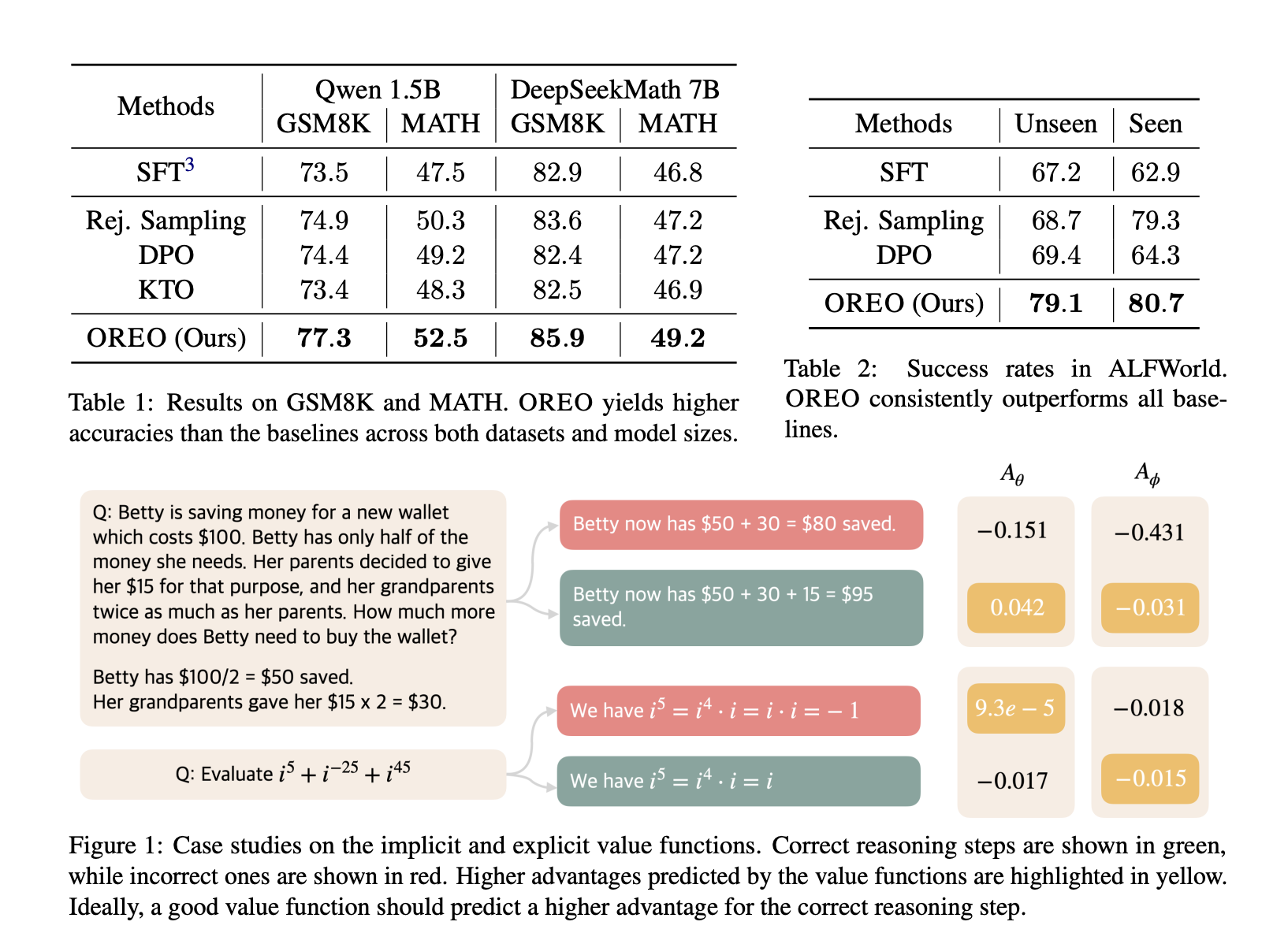
Результаты и выводы
OREO была протестирована на различных задачах, таких как GSM8K и MATH. Основные результаты:
- На GSM8K OREO показала 5.2% улучшение точности по сравнению с другими методами.
- В ALFWorld OREO достигла 17.7% улучшения в новых условиях.
- Итеративное обучение увеличило эффективность OREO, демонстрируя стабильные приросты точности.
Заключение
OREO представляет собой практическое решение для улучшения многоступенчатого мышления LLM через оффлайн обучение с подкреплением. Интеграция детального распределения «кредита» и итеративного обучения делает OREO универсальным инструментом для сложных задач.
Если вам нужна помощь в внедрении ИИ в вашу компанию, проанализируйте, как ИИ может улучшить ваши процессы. Определите ключевые показатели эффективности и подберите подходящее решение. Внедряйте ИИ постепенно и расширяйте автоматизацию на основе полученных данных.
«`



















