
Embedić: Новое слово в сфере обработки сербского языка
Embedić: ключевые особенности и практическое применение
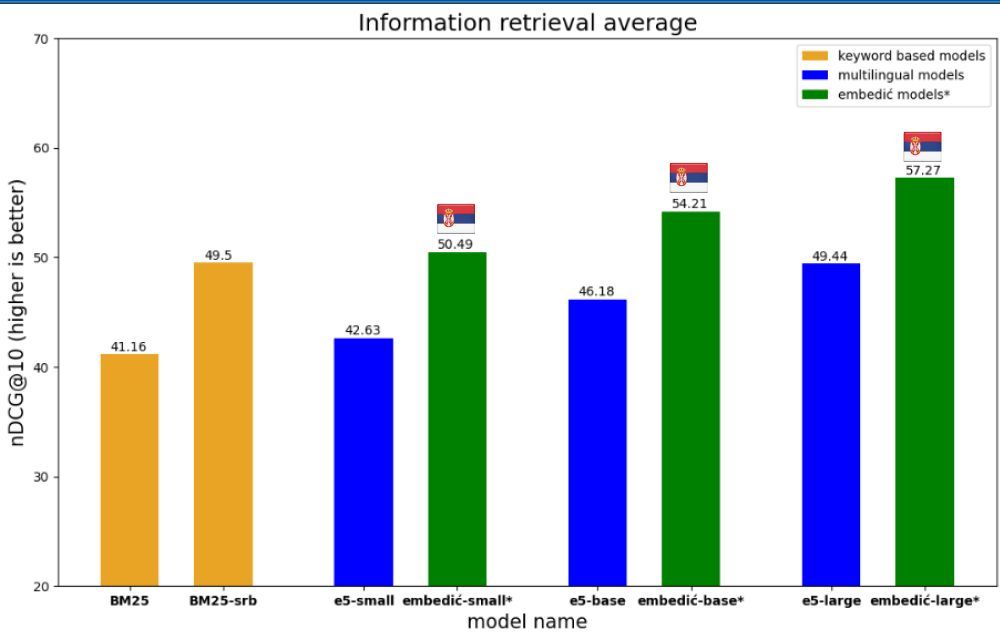
Novak Zivanic внес значительный вклад в область обработки естественного языка с выпуском Embedić — набора моделей встраивания текста на сербском языке. Эти модели специально разработаны для задач информационного поиска и генерации с использованием метода Retrieval-Augmented Generation (RAG). Самая маленькая модель в наборе достигла выдающихся результатов, превзойдя предыдущие показатели производительности при использовании в 5 раз меньшего количества параметров. Этот прорыв демонстрирует эффективность и эффективность моделей Embedić в обработке сербского языка.
Модели Embedić настраиваются на основе мультиязычных моделей-e5 и представлены в трех размерах (small, base и large).
Набор Embedić проявляет впечатляющую универсальность в своих языковых возможностях. Хотя специализированы для сербского языка, включая как кириллицу, так и латиницу, эти модели также обладают кросс-языковой функциональностью, понимая также английский язык. Эта функция позволяет пользователям встраивать документы на английском, сербском или их комбинации. Используя фреймворк sentence-transformers, Embedić отображает предложения и абзацы в 786-мерное плотное векторное пространство. Это представление делает модели особенно полезными для задач, таких как кластеризация и семантический поиск, улучшая их практическое применение в различных лингвистических контекстах.
При использовании Embedić важно учитывать некоторые важные рекомендации по использованию. Использование «ошшана латиница» (упрощенный латинский алфавит без диакритических знаков) может значительно снизить качество поиска, поэтому рекомендуется использовать правильную сербскую орфографию. Кроме того, применение заглавных букв для именованных сущностей может заметно улучшить результаты поиска.
Набор Embedić предлагает три размера моделей: small, base и large, все они настраиваются на основе мультиязычных моделей-e5. Процесс обучения, проведенный на одном 4070ti Super GPU, включает три этапа: дистилляцию, обучение на парах (запрос, текст) и окончательное донастройку с триплетами.
Модели Embedić прошли тщательную оценку по трем ключевым задачам: информационный поиск, сходство предложений и майнинг битекстов. Для обеспечения комплексной оценки были затрачены значительные усилия и ресурсы на создание подходящих наборов данных на сербском языке. Разработчик лично перевел набор данных STS17 для кросс-языковой оценки, продемонстрировав приверженность точности. Кроме того, были вложены средства в размере $6,000 в Google Translation API для преобразования четырех наборов данных по информационному поиску на сербский язык. Этот тщательный подход к подготовке наборов данных подчеркивает основательность процесса оценки и потенциальную эффективность моделей в задачах на сербском языке.
Выпуск Embedić является значительным прорывом в обработке сербского языка. Разработанный Новаком Зиваничем, этот набор моделей встраивания текста предлагает передовую производительность для задач информационного поиска и RAG, причем самая маленькая модель превосходит предыдущие стандарты, используя значительно меньше параметров. Модели, доступные в трех размерах, настраиваются на основе мультиязычных моделей-e5 и обладают кросс-языковыми возможностями, понимая как сербский (кириллица и латиница), так и английский язык.
Применение и практические советы
Если вы хотите, чтобы ваша компания использовала преимущества искусственного интеллекта (ИИ) и оставалась на шаг впереди, умело применяйте Embedić — набор моделей встраивания текста на сербском языке, оптимизированный для информационного поиска и RAG.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где можно внедрить автоматизацию: найдите моменты, когда ваши клиенты могут извлечь пользу из ИИ.
Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
Выберите подходящее решение, поскольку сейчас существует множество вариантов ИИ. Внедряйте ИИ-решения постепенно: начните с небольшого проекта, анализируйте результаты и KPI.
На основе данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI-ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru — будущее уже здесь!



















