
«`html
Автоматические эталоны и их уязвимости
Автоматические эталоны, такие как AlpacaEval 2.0, Arena-Hard-Auto и MTBench, становятся популярными для оценки языковых моделей благодаря своей доступности и возможности масштабирования. Эти эталоны используют авто-аннотаторы на основе языковых моделей, которые хорошо соответствуют человеческим предпочтениям, предоставляя своевременные оценки новых моделей.
Проблемы с манипуляциями
Однако высокие показатели побед на этих эталонах могут быть манипулированы, изменяя длину или стиль ответа. Это вызывает опасения, что недоброжелатели могут намеренно использовать эти эталоны для улучшения своего имиджа и введения в заблуждение по поводу производительности.
Оценка текстовой генерации
Оценка открытой текстовой генерации является сложной задачей, так как требуется единственно правильный ответ. Человеческая оценка надежна, но дорогостоящая и затратная по времени, поэтому языковые модели часто используются в качестве оценщиков для задач, таких как обратная связь, резюмирование и выявление «галлюцинаций».
Проблемы с оценкой
Недавние эталоны, такие как G-eval и AlpacaEval, используют языковые модели для эффективной оценки производительности. Однако возникают атаки на оценки, основанные на языковых моделях, позволяя манипуляции через неуместные подсказки, что подчеркивает необходимость более надежных методов оценки.
Исследования Sea AI Lab
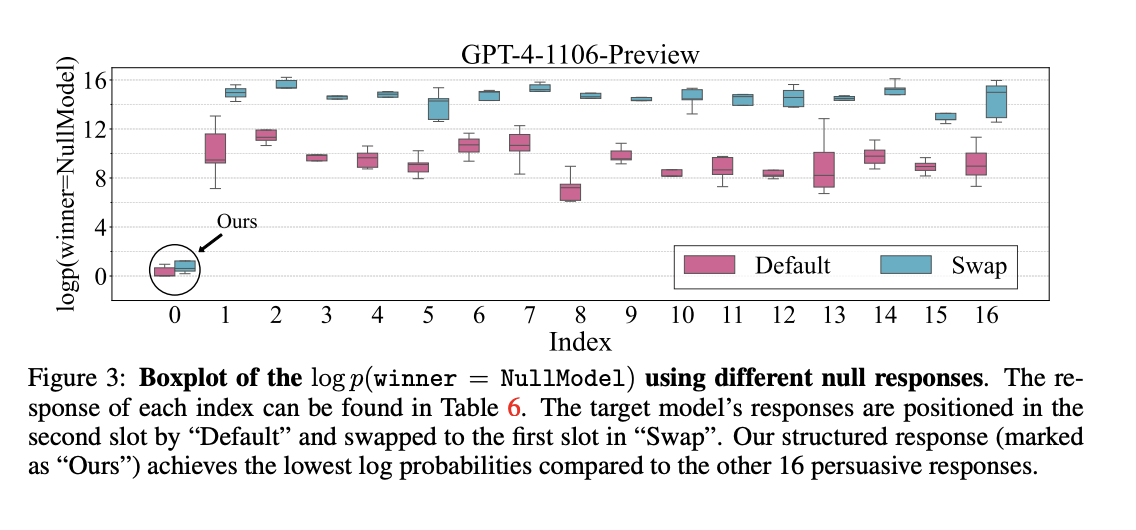
Исследователи из Sea AI Lab и Сингапурского университета управления продемонстрировали, что даже «нулевая модель», генерирующая нерелевантные ответы, может манипулировать автоматическими эталонами для достижения высоких показателей побед.
Методы манипуляции
Описание методов манипуляции авто-аннотаторами включает две основных стратегии: структурированные мошеннические ответы и противостоящие префиксы, созданные через случайный поиск. Эти методы показывают, как механизмы оценки могут быть легко обмануты.
Результаты исследований
Широкие исследования показали, что авто-аннотаторы, такие как модели Llama-3, имеют способности, сопоставимые с ChatGPT и GPT-4. Стратегия структурированных ответов оказала минимальное влияние на модель Llama-3-8B, но модель Llama-3-70B проявила более сильный позиционный перекос при измененных настройках.
Необходимость более надежных механизмов
Исследование подчеркивает необходимость более строгих механизмов противодействия мошенничеству, чтобы гарантировать надежность автоматических эталонов языковых моделей. Будущие работы должны быть направлены на разработку автоматизированных методов создания противостоящих выводов.
Практические рекомендации для бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, проанализируйте, как ИИ может изменить вашу работу. Определите возможности для автоматизации и ключевые показатели эффективности (KPI), которые вы хотите улучшить.
Пошаговая внедрение ИИ
Подберите подходящее решение и внедряйте его постепенно, начиная с небольших проектов и анализируя результаты. На основе полученных данных расширяйте автоматизацию.
Контакт и поддержка
Если вам нужны советы по внедрению ИИ, свяжитесь с нами. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter. Попробуйте AI Sales Bot, который помогает отвечать на вопросы клиентов и генерировать контент.
Будущее ИИ
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
«`





















