
Введение в моделирование встраивания
Недавние достижения в области моделей встраивания направлены на преобразование универсальных текстовых представлений для различных приложений, таких как семантическая схожесть, кластеризация и классификация. Традиционные модели встраивания, такие как Universal Sentence Encoder и Sentence-T5, стремились предоставить общие текстовые представления, но последние исследования выявили их ограничения в обобщении.
Инновации благодаря большим языковым моделям
Интеграция больших языковых моделей (LLM) революционизировала разработку моделей встраивания через два основных подхода: улучшение тренировочных наборов данных с помощью генерации синтетических данных и жесткой выборки негативов, а также использование параметров предобученных LLM для инициализации. Эти методы значительно повышают качество встраивания и производительность задач, хотя могут увеличивать вычислительные затраты.
Адаптация предобученных LLM
Недавние исследования также изучили адаптацию предобученных LLM для задач встраивания. Модели, такие как Sentence-BERT, DPR и Contriever, продемонстрировали преимущества контрастивного обучения и языково-независимой тренировки. Новейшие модели, такие как E5-Mistral и LaBSE, инициализированные от LLM, таких как GPT-3 и Mistral, превзошли традиционные встраивания на основе BERT и T5.
Представление модели Gemini Embedding
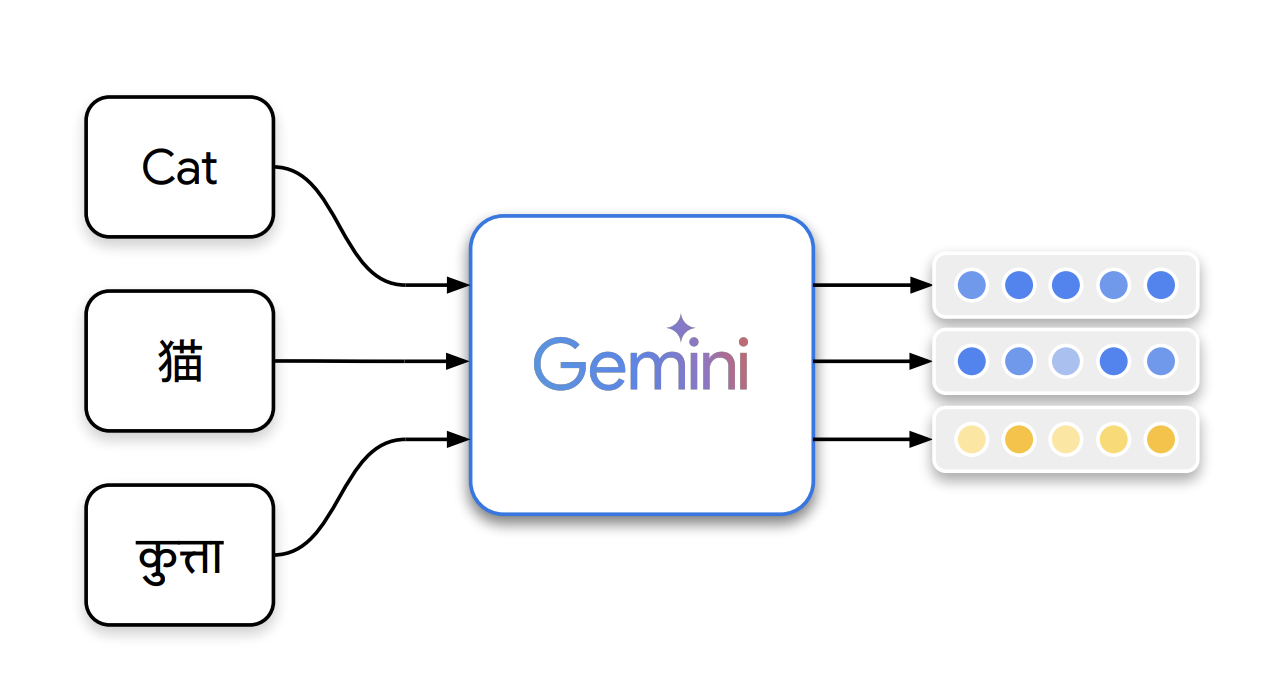
Команда Gemini Embedding в Google представила модель Gemini Embedding, которая генерирует высоко обобщаемые текстовые представления. Модель основывается на мощной большой языковой модели Gemini и использует многоязычные и кодовые возможности для повышения качества встраивания в различных задачах, таких как извлечение и семантическая схожесть.
Процесс тренировки
Модель тренируется с использованием высококачественного, гетерогенного набора данных, отобранного с помощью фильтрации Gemini, выбора положительных и отрицательных фрагментов, а также генерации синтетических данных. Gemini Embedding достигает лучших результатов на Massive Multilingual Text Embedding Benchmark (MMTEB) через контрастивное обучение и дообучение.
Эффективность и результаты
Gemini Embedding была оценена по нескольким бенчмаркам, включая многоязычные и кодовые задачи, и продемонстрировала превосходство в классификации, кластеризации и извлечении информации. Модель заняла высшие позиции по баллам Борды и превзошла конкурентов в задачах, связанных с кодом.
Заключение и рекомендации
В заключение, модель Gemini Embedding является мощным многоязычным решением для задач классификации, извлечения и ранжирования. Для повышения качества модель использует синтетическую генерацию данных, фильтрацию наборов данных и жесткую выборку негативов. Будущие исследования направлены на расширение возможностей модели для мультимодальных встраиваний. Оценки на больших многоязычных бенчмарках подтверждают её превосходство.
Как искусственный интеллект может улучшить ваш бизнес
- Изучите, как технологии ИИ могут изменить ваш подход к работе.
- Определите важные KPI, чтобы гарантировать положительное влияние инвестиций в ИИ на бизнес.
- Выберите инструменты, соответствующие вашим потребностям и позволяющие вам настраивать их в соответствии с вашими целями.
- Начните с небольшого проекта, соберите данные о его эффективности и постепенно расширяйте использование ИИ.
Если вам нужна помощь в управлении ИИ в вашем бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Подписывайтесь на наш Telegram здесь.
Посмотрите практический пример решения на основе ИИ: бота для продаж, разработанного для автоматизации взаимодействия с клиентами круглосуточно.



















