
«`html
Модели Генеративного Вознаграждения (GenRM): Гибкий Подход к Обучению с Поддержкой Человеческой и ИИ Обратной Связи
Обучение с подкреплением (RL) стало важным шагом в развитии искусственного интеллекта (ИИ), позволяя моделям учиться на основе взаимодействия с окружающей средой. Недавний подход, известный как Обучение с Подкреплением на Основе Человеческой Обратной Связи (RLHF), значительно улучшил большие языковые модели (LLM), включая человеческие предпочтения в процесс обучения.
Проблемы и Решения
Сбор и обработка обратной связи от людей требует много ресурсов и больших наборов данных. Это создает узкие места в разработке моделей и ограничивает их способность адаптироваться к новым задачам. Чтобы решить эту проблему, необходимо уменьшить зависимость от человеческих данных и улучшить обобщение моделей.
Недавний подход, Обучение с Подкреплением на Основе Обратной Связи ИИ (RLAIF), использует обратную связь, генерируемую ИИ, но исследования показывают, что такая обратная связь может не совпадать с реальными человеческими предпочтениями. Это особенно заметно в задачах, выходящих за пределы привычного (OOD).
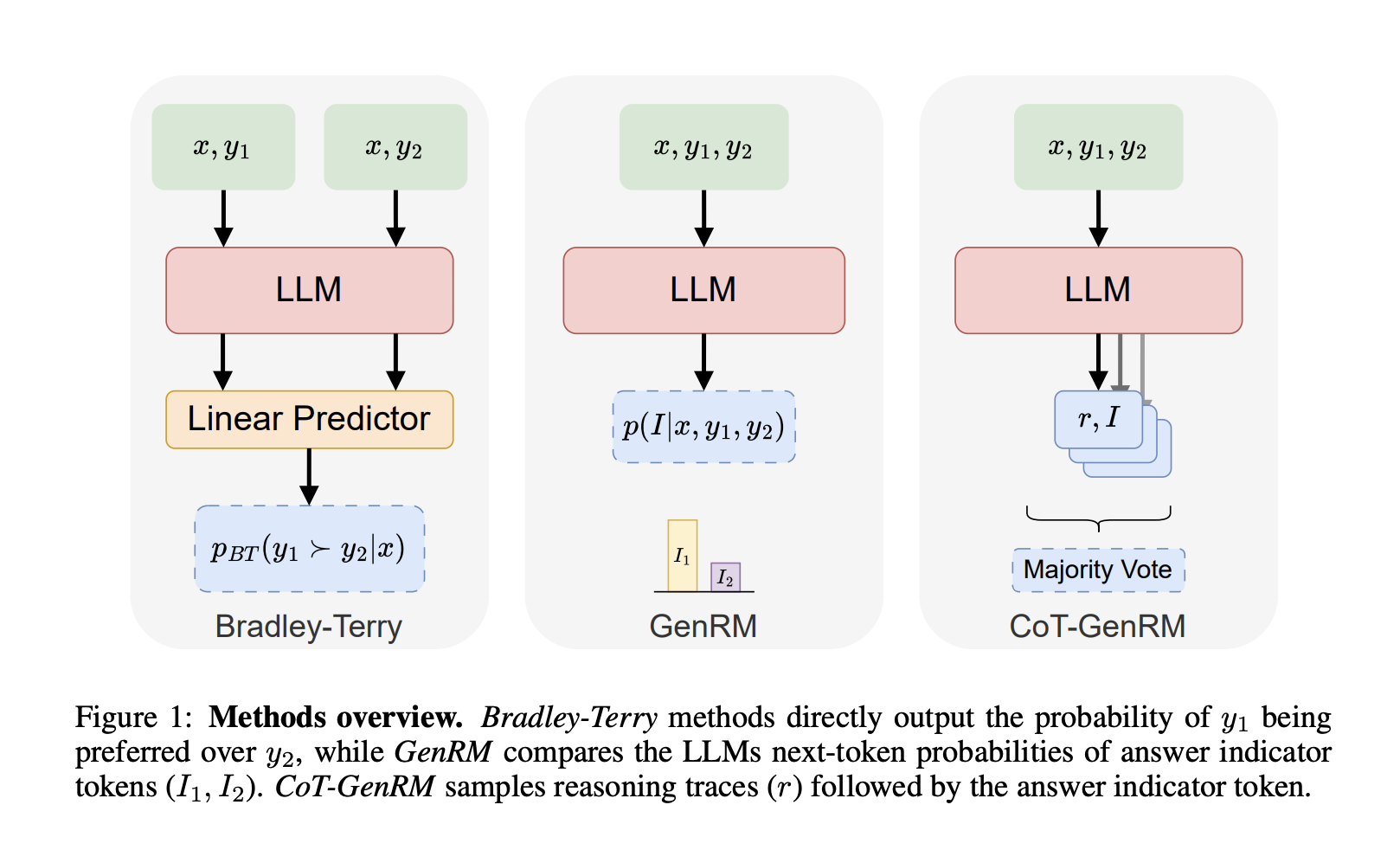
Генеративные Модели Вознаграждения (GenRM)
Исследователи из SynthLabs и Стэнфордского университета предложили гибридное решение — Генеративные Модели Вознаграждения (GenRM). Этот метод сочетает сильные стороны RLHF и RLAIF, позволяя моделям учиться более эффективно. GenRM использует итеративный процесс для уточнения LLM, генерируя синтетические метки предпочтений, которые лучше отражают человеческие ожидания.
Преимущества GenRM
- Увеличение производительности: GenRM улучшает производительность на задачах в распределении на 9-31% и на задачах OOD на 10-45%.
- Снижение зависимости от человеческой обратной связи: Генерируемые ИИ цепочки рассуждений заменяют необходимость в больших наборах данных с метками от людей.
- Улучшение обобщения: GenRM показывает на 26% лучшие результаты в незнакомых задачах по сравнению с традиционными моделями.
- Сбалансированный подход: Гибридное использование ИИ и человеческой обратной связи обеспечивает соответствие систем ИИ человеческим ценностям.
- Итеративное обучение: Непрерывное уточнение через цепочки рассуждений улучшает принятие решений в сложных задачах.
В заключение, Генеративные Модели Вознаграждения представляют собой мощный шаг вперед в обучении с подкреплением. Они решают две ключевые проблемы: уменьшают необходимость в трудоемком сборе данных и улучшают способность моделей справляться с новыми задачами. GenRM является масштабируемым и адаптируемым решением для повышения соответствия ИИ человеческим ценностям.
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, используйте Генеративные Модели Вознаграждения. Проанализируйте, как ИИ может изменить вашу работу, определите ключевые показатели эффективности (KPI) и внедряйте ИИ решения постепенно.
Если вам нужны советы по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем Telegram-канале или в Twitter.
Попробуйте AI Sales Bot, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`



















