
«`html
Улучшение 3D генерации с помощью DreamHOI
Ранее методы генерации 3D моделей сосредотачивались на использовании моделей, специфичных для категорий, и работе с одним изображением. Недавние достижения включают использование предварительно обученных генераторов изображений и видео, особенно моделей диффузии, для создания моделей в открытом домене. Тонкая настройка на многовидовых наборах данных улучшила результаты, но остались вызовы в создании сложных композиций и взаимодействий. Попытки улучшить композициональность в моделях генерации изображений столкнулись с трудностями в передаче техник на генерацию 3D моделей. Некоторые методы расширили подходы к дистилляции для композиционной генерации 3D моделей, оптимизируя отдельные объекты и пространственные отношения, соблюдая физические ограничения.
Синтез взаимодействия человек-объект
Методы, такие как InterFusion, развивают синтез взаимодействия на основе текстовых подсказок. Однако ограничения в управлении идентичностью человека и объекта остаются. Многие подходы сталкиваются с проблемой сохранения идентичности и структуры человеческой сетки во время генерации взаимодействия. Эти вызовы подчеркивают необходимость более эффективных техник, позволяющих больший контроль пользователю и практическую интеграцию в производственные процессы виртуальной среды.
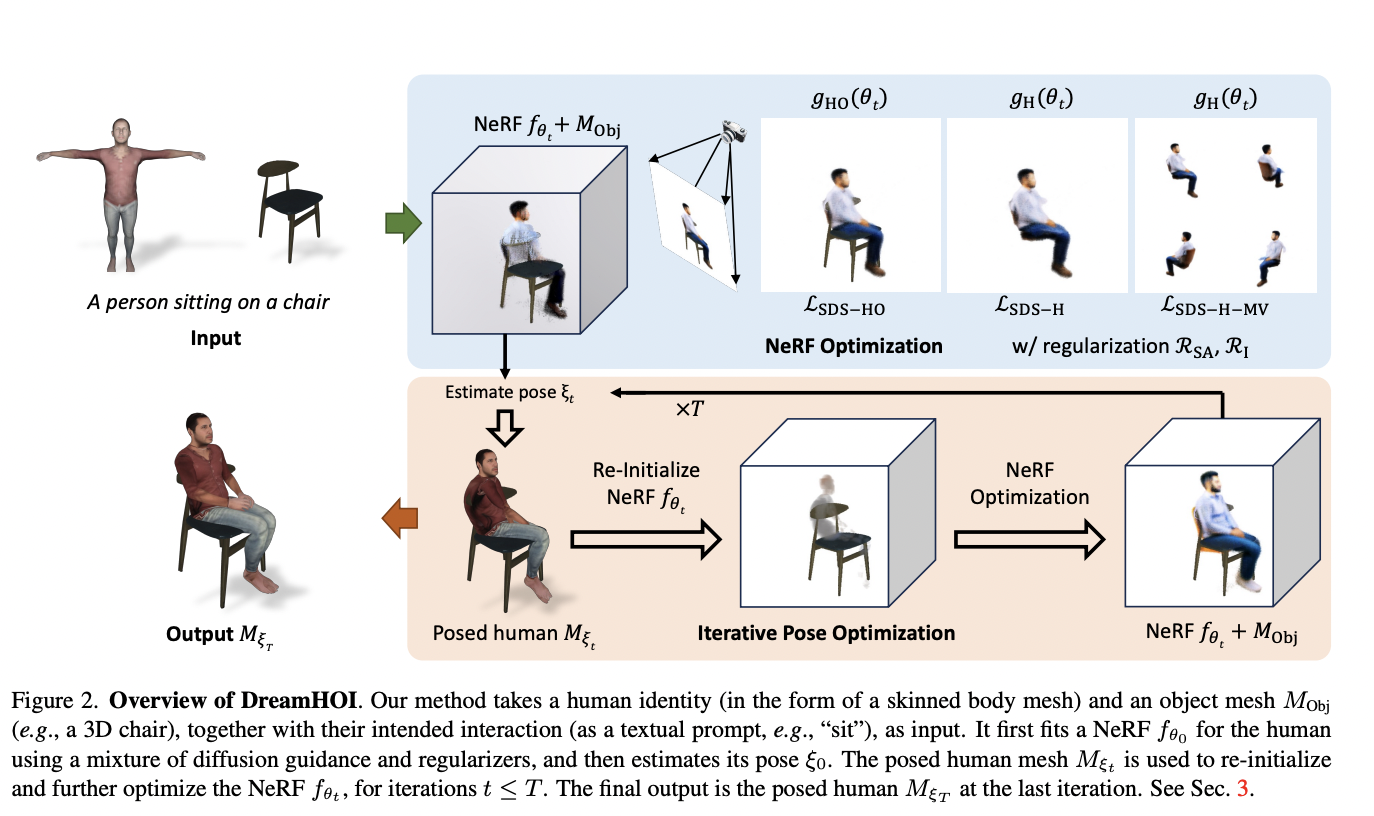
Революционный подход DreamHOI
Исследователи из Университета Оксфорда и Университета Карнеги-Меллона представили метод нулевой настройки для синтеза 3D взаимодействия человек-объект с использованием текстовых описаний. Подход использует модели диффузии текста в изображение для решения вызовов, связанных с разнообразной геометрией объектов и ограниченными наборами данных. Он оптимизирует артикуляцию человеческой сетки с помощью градиентов выборочной дистилляции из этих моделей. Метод использует двойное неявно-явное представление, объединяя нейронные радиационные поля с артикуляцией сетки, управляемой скелетом, для сохранения идентичности персонажа. Этот инновационный подход позволяет создавать реалистичные взаимодействия человека с объектами без обширного сбора данных, продвигая область синтеза 3D взаимодействия.
Превосходство DreamHOI
Метод DreamHOI превосходит базовые методы с более высокими оценками сходства CLIP. Его двойное неявно-явное представление объединяет нейронные радиационные поля и артикуляцию сетки, позволяя гибкую оптимизацию позы, сохраняя при этом идентичность персонажа. Двухэтапный процесс оптимизации, включающий 5000 шагов улучшения NeRF, способствует высококачественным результатам. Регуляризаторы играют важную роль в поддержании правильного размера и выравнивания модели. Регрессор облегчает переходы между NeRF и сетчатыми представлениями. DreamHOI преодолевает ограничения методов, таких как DreamFusion, в поддержании идентичности и структуры сетки.
Выводы
Метод DreamHOI представляет новаторский подход для создания реалистичных взаимодействий человека с объектами в 3D с использованием текстовых описаний и моделей диффузии. Экспериментальные результаты демонстрируют превосходство DreamHOI по сравнению с базовыми методами, а абляционные исследования подтверждают важность каждого компонента. Этот прогресс открывает новые возможности для применения в индустрии развлечений и не только.
Подробнее об исследовании читайте на странице Paper and Project Page.
Авторы исследования: Researchers of this project.
Следите за нашими новостями в Twitter и присоединяйтесь к нашим группам в Telegram и LinkedIn.
Присоединяйтесь к нашему сообществу в ML SubReddit.
Бесплатный вебинар: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (ср, 25 сентября, 11:00 – 11:45 по МСК).