
«`html
Новые возможности в области больших мультимодальных моделей (LMM)
Недавние успехи в области больших мультимодальных моделей (LMM) продемонстрировали замечательные способности в различных мультимодальных ситуациях, приближаясь к цели искусственного общего интеллекта. За счет использования больших объемов данных о визуально-языковых данных, они усовершенствуют LMM с визуальными возможностями путем выравнивания визуальных кодировщиков.
Необходимость новых подходов к LMM
Большинство открытых LMM сфокусированы преимущественно на сценариях с одним изображением, оставляя более сложные сценарии с несколькими изображениями практически неисследованными. Это важно, поскольку многие приложения реального мира требуют возможности работы с несколькими изображениями, такими как тщательный анализ нескольких изображений.
Практические решения и значимость
Для решения этих проблем авторы обсуждают некоторые смежные работы. Одно из них — это данных смешанного типа изображений и текста, которые предоставляют LMM две ключевые возможности: мультимодальное контекстное обучение (ICL) и выполнение инструкций в реальных сценариях с множеством изображений.
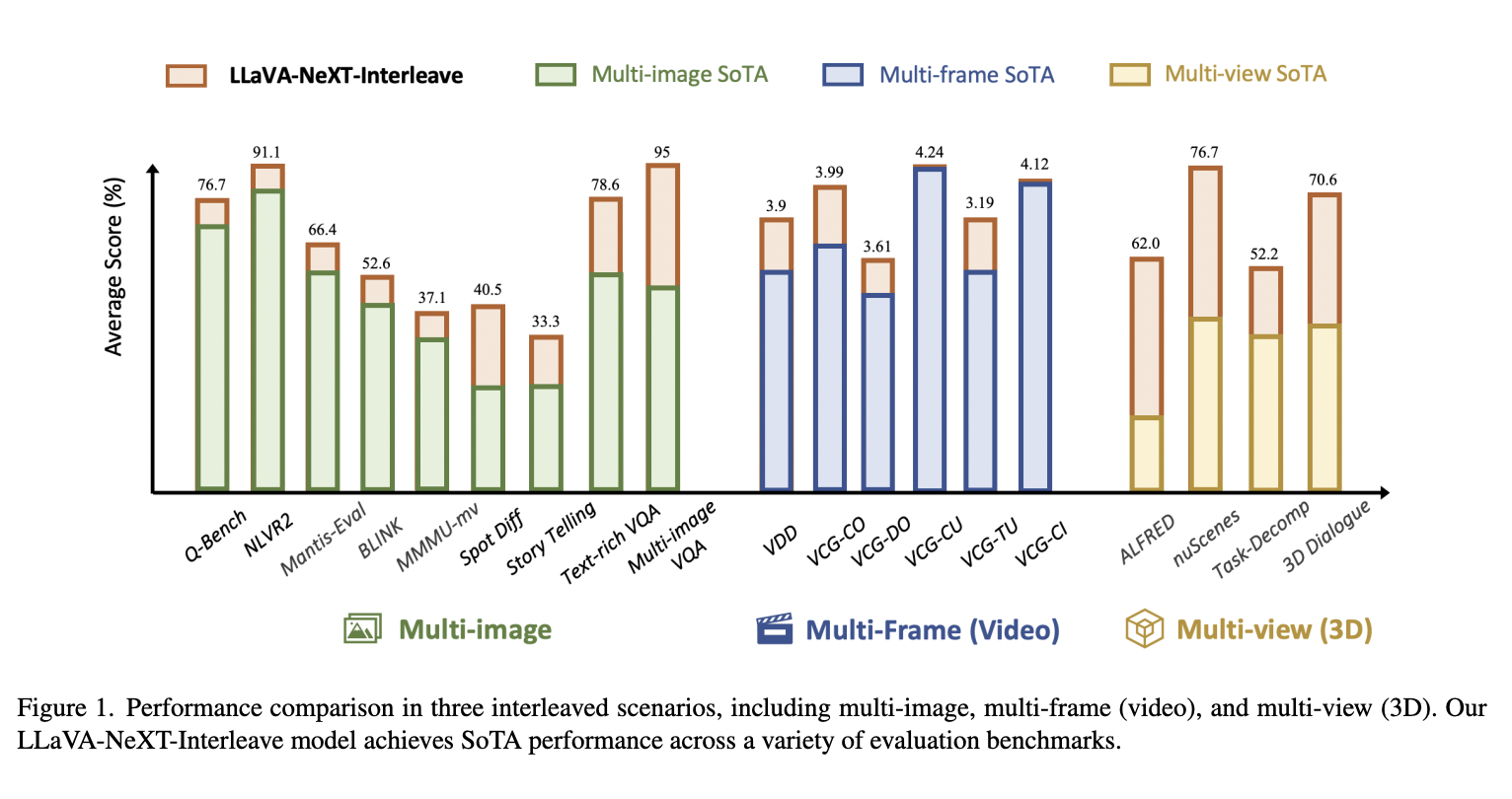
Результаты исследований
Исследователи из нескольких университетов предложили LLaVA-NeXT-Interleave — универсальную LMM, способную обрабатывать различные реальные сценарии, такие как множественные изображения, многокадровые (видео), многозрительные (3D) данные, сохраняя производительность на уровне одного изображения. Этот подход создает новые стандарты в области мультимодального ИИ и сложных задач визуального понимания.
Практическая польза
Не забудьте просмотреть статью и GitHub. Поддержите авторов этого исследования и следите за нами в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn. И если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему Reddit-сообществу ML SubReddit.