
«`html
Protein Annotation-Improved Representations (PAIR): A Flexible Fine-Tuning Framework that Employs a Text Decoder to Guide the Fine-Tuning Process of the Encoder
Языковые модели белков (PLM) обучаются на больших базах данных белков для прогнозирования последовательностей аминокислот и создания векторов признаков, представляющих белки. Эти модели доказали свою полезность в различных приложениях, таких как прогнозирование складывания белков и эффектов мутаций. Одной из ключевых причин их успеха является способность захватывать сохраненные последовательные мотивы, которые часто важны для подгонки белка. Однако эволюционные и окружающие факторы могут влиять на связь между сохранением последовательности и подгонкой белка, что делает ее сложной. PLM основаны на псевдологарифмических целях, но включение дополнительных источников данных, таких как текстовые аннотации, описывающие функции и структуры белков, может улучшить их точность.
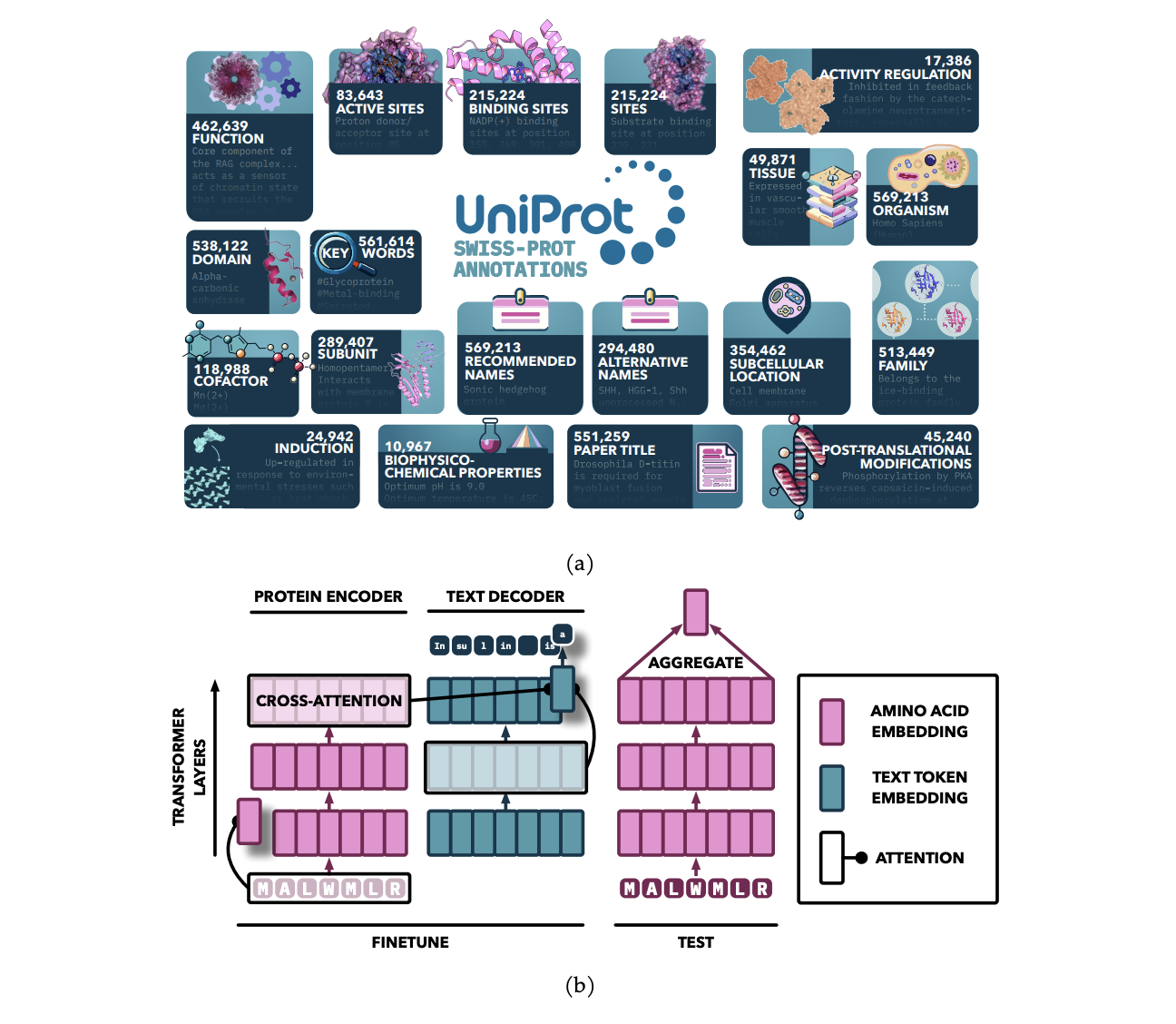
Исследователи из Университета Торонто и Института Вектор провели исследование, которое улучшило PLM, настраивая их с помощью текстовых аннотаций из UniProt, сосредотачиваясь на девятнадцати типах экспертных данных. Они представили фреймворк Protein Annotation-Improved Representations (PAIR), который использует текстовый декодер для направления обучения модели. PAIR значительно улучшил производительность моделей в задачах прогнозирования функций, даже превзойдя алгоритм поиска BLAST, особенно для белков с низкой схожестью последовательностей с обучающими данными. Этот подход подчеркивает потенциал включения разнообразных текстовых аннотаций для продвижения обучения представлений белков.
Область маркировки белков традиционно полагается на методы, такие как BLAST, который обнаруживает гомологию последовательностей белков через выравнивание последовательностей, и скрытые модели Маркова (HMM), которые включают дополнительные данные, такие как семейство белков и эволюционную информацию. Эти классические подходы хорошо справляются с последовательностями с высокой схожестью, но испытывают трудности с обнаружением дальней гомологии. Эта проблема привела к развитию PLM, которые применяют техники глубокого обучения для изучения представлений белков из масштабных данных последовательностей, вдохновленные моделями обработки естественного языка. Недавние достижения также интегрируют текстовые аннотации, с моделями, такими как ProtST, использующими разнообразные источники данных для улучшения прогнозирования функций белков.
Модель использует архитектуру последовательности-к-последовательности на основе внимания, инициализированную предварительно обученными моделями и улучшенную добавлением кросс-внимания между кодировщиком и декодером. Кодировщик обрабатывает последовательности белков в непрерывные представления с использованием самовнимания, в то время как декодер генерирует текстовые аннотации авторегрессивным образом. Предварительно обученные модели белков из семейств ProtT5 и ESM служат в качестве кодировщика, в то время как SciBERT является текстовым декодером. Модель обучается на нескольких типах аннотаций с использованием специализированного подхода к выборке, обучение проводится на кластере HPC с использованием многократного обучения с использованием буфера bfloat16.
Фреймворк PAIR улучшает прогнозирование функций белков путем настройки предварительно обученных моделей трансформера, таких как ESM и ProtT5, на высококачественных аннотациях из баз данных, таких как Swiss-Prot. Интегрируя кросс-внимание, PAIR позволяет текстовым токенам обращаться к последовательностям аминокислот, улучшая связь между последовательностями белков и их аннотациями. PAIR значительно превосходит традиционные методы, такие как BLAST, особенно для белков с низкой схожестью последовательностей, и проявляет сильную обобщаемость к новым задачам. Его способность обрабатывать сценарии ограниченных данных делает его ценным инструментом в биоинформатике и прогнозировании функций белков.
Фреймворк PAIR улучшает представления белков, используя разнообразные текстовые аннотации, которые захватывают важные функциональные свойства. Объединяя эти аннотации, PAIR значительно улучшает прогнозирование различных функциональных свойств, включая те, которые ранее не были характеризованы. PAIR последовательно превосходит базовые языковые модели белков и традиционные методы, такие как BLAST, особенно для последовательностей с низкой схожестью с обучающими данными. Результаты указывают на то, что включение дополнительных модальностей данных, таких как трехмерная структурная информация или геномные данные, может обогатить представления белков. Гибкий дизайн PAIR также имеет потенциальные применения для представления других биологических объектов, таких как малые молекулы и нуклеиновые кислоты.
Проверьте статью и модель. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI выпустил DistillKit: Open Source, простой в использовании инструмент для трансформации моделирования для создания эффективных, высокопроизводительных малых языковых моделей
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Protein Annotation-Improved Representations (PAIR): A Flexible Fine-Tuning Framework that Employs a Text Decoder to Guide the Fine-Tuning Process of the Encoder.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter itinairu45358
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`





















