Введение
Данная работа от ByteDance представляет гибридную систему вознаграждений, объединяющую проверку задач на рассуждение (RTV) и генеративную модель вознаграждения (GenRM) для предотвращения манипуляций с вознаграждениями.
Проблемы и решения
Обучение с подкреплением на основе человеческой обратной связи (RLHF) играет ключевую роль в согласовании больших языковых моделей (LLM) с человеческими ценностями и предпочтениями. Несмотря на альтернативные подходы, такие как DPO, ведущие модели, включая ChatGPT/GPT-4, продолжают использовать алгоритмы RL, такие как PPO.
Качество модели вознаграждения критично для успеха RLHF, и оно сталкивается с тремя основными проблемами: некорректное моделирование предпочтений, неясные предпочтения в обучающих наборах данных и плохая способность к обобщению. Для решения этих проблем была предложена модель GenRM, которая показывает устойчивость к манипуляциям с вознаграждениями.
Гибридная система вознаграждений
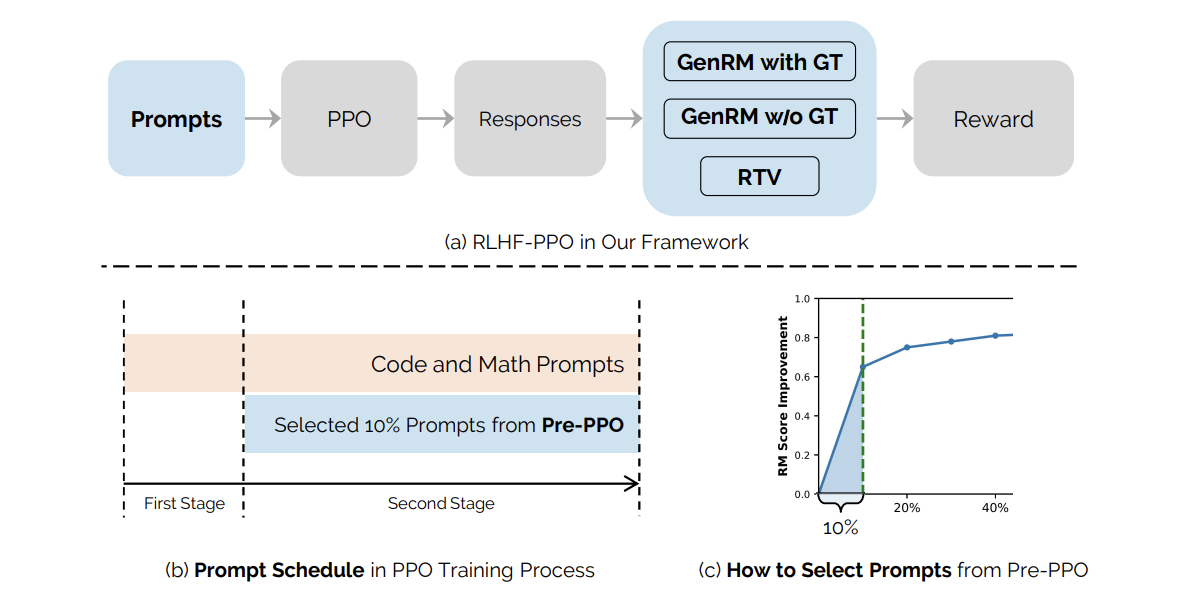
Исследователи из ByteDance Seed предложили гибридную систему, комбинирующую RTV и GenRM, что позволяет более точно оценивать ответы на основе истинных решений. Также была внедрена новая методика выбора подсказок под названием Pre-PPO, которая помогает выявлять более сложные обучающие подсказки, менее подверженные манипуляциям с вознаграждениями.
Экспериментальные результаты
В рамках эксперимента использовались две предобученные языковые модели различного масштаба: меньшая с 25B параметрами и большая с 150B параметрами. Набор данных содержал один миллион подсказок из различных областей, включая математику, программирование и логическое рассуждение.
Результаты показали, что предложенный подход улучшает показатели на +1.1 по сравнению с базовым методом и до +1.4 на более сложном наборе данных. Наибольшие улучшения были достигнуты в математических и кодирующих задачах.
Заключение
Предложенный подход помогает преодолеть основные проблемы в масштабировании данных RLHF, такие как манипуляции с вознаграждениями и снижение разнообразия ответов. Комбинированный подход с стратегическим построением подсказок и приоритетом на ранних стадиях обучения демонстрирует эффективность и устойчивость к манипуляциям.
Практические рекомендации для бизнеса
Изучите, какие процессы можно автоматизировать, и определите моменты взаимодействия с клиентами, где ИИ может добавить максимальную ценность.
Определите ключевые показатели эффективности (KPI), чтобы убедиться, что ваши инвестиции в ИИ приносят положительные результаты для бизнеса.
Выберите инструменты, которые соответствуют вашим потребностям и позволяют настраивать их под ваши цели.
Начните с небольшого проекта, соберите данные о его эффективности и постепенно расширяйте использование ИИ в своей работе.
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей об ИИ, подписывайтесь на наш Telegram.
Пример решения на основе ИИ
Посмотрите практический пример решения на основе ИИ: бот для продаж от itinai.ru, созданный для автоматизации общения с клиентами круглосуточно и управления взаимодействиями на всех этапах клиентского пути.