
«`html
Биомедицинская обработка естественного языка (NLP)
Биомедицинская обработка естественного языка (NLP) сосредотачивается на разработке моделей машинного обучения для интерпретации и анализа медицинских текстов. Эти модели помогают с диагностикой, рекомендациями по лечению и извлечением медицинской информации, значительно улучшая предоставление медицинской помощи и клиническое принятие решений. Через обработку огромного объема биомедицинской литературы и записей пациентов, эти модели помогают выявлять закономерности и идеи, которые могут привести к лучшим результатам для пациентов и более информированным медицинским исследованиям.
Используемые модели и вызовы в биомедицинской NLP
Одним из серьезных вызовов в биомедицинской NLP является обеспечение устойчивости и точности языковых моделей при работе с разнообразными и контекстно-специфическими медицинскими терминологиями. Вариации в наименованиях лекарств, особенно между общими и торговыми названиями, могут вызывать несоответствия и ошибки в выходных данных модели. Эти несоответствия могут влиять на уход за пациентами и клинические решения, поскольку различные терминологии могут использоваться взаимозаменяемо медицинскими специалистами и пациентами, что может привести к недопониманиям или неправильным медицинским рекомендациям.
Новый метод оценки устойчивости и точности языковых моделей
Исследователи из MIT, Гарварда и Mass General Brigham вместе с другими ведущими институтами представили новый метод оценки устойчивости для решения этой проблемы. Они разработали специализированный набор данных под названием RABBITS (Robust Assessment of Biomedical Benchmarks Involving Drug Term Substitutions) для оценки производительности языковых моделей путем замены торговых и общих названий лекарств. Этот инновационный подход стремится имитировать реальную изменчивость в наименовании лекарств и предоставлять более точную оценку способностей языковых моделей в обработке медицинской терминологии.
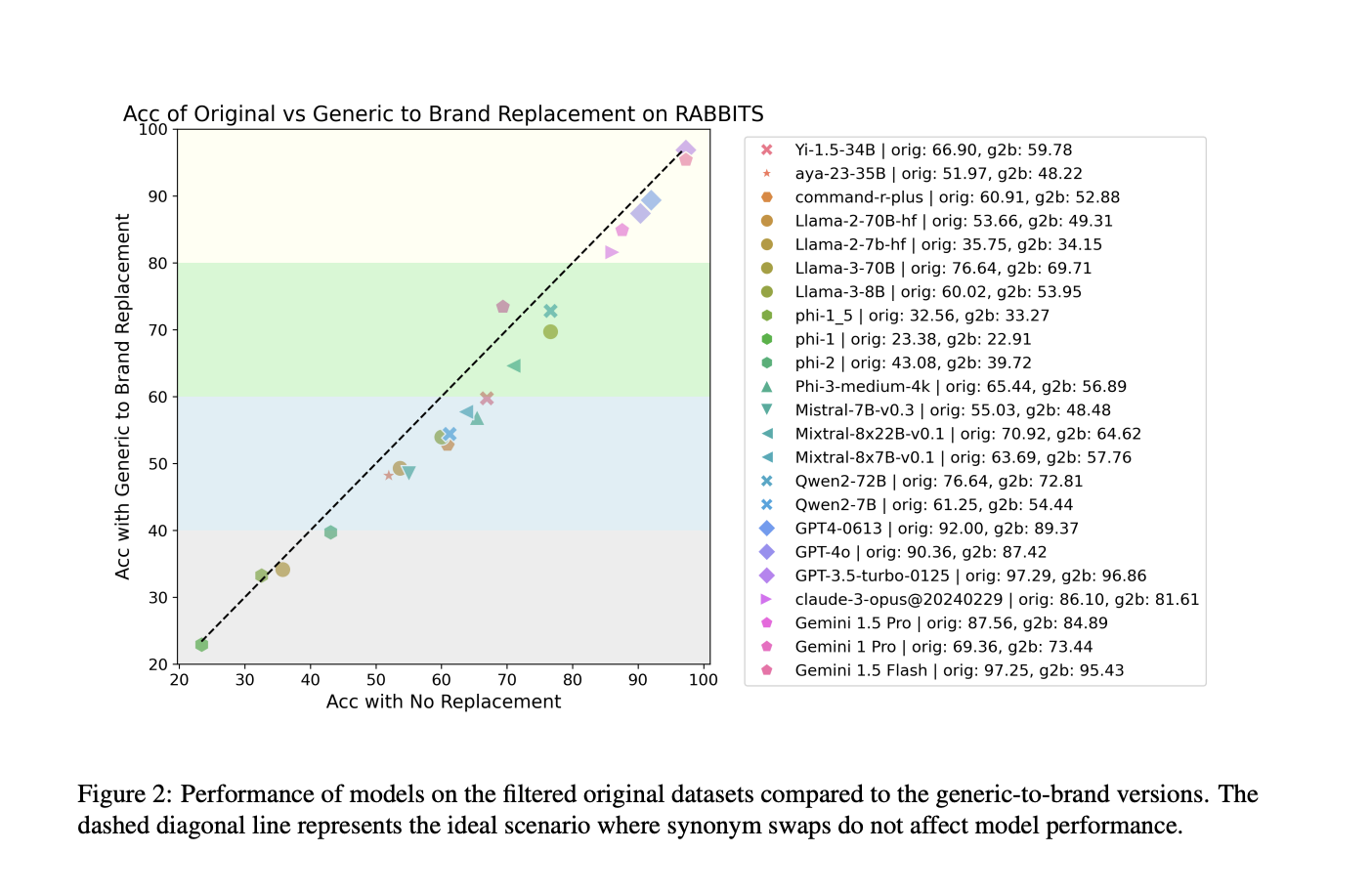
Результаты и значимость исследования
Исследование выявило значительное снижение производительности больших языковых моделей (LLMs) при замене наименований лекарств. Например, модель Llama-3-70B, которая имела точность 76,6% на исходном наборе данных, снизилась до 69,7% точности при замене общих на торговые названия. Исследователи обнаружили, что открытые модели от 7B и выше последовательно падали ниже идеальной линии устойчивости, указывая на снижение производительности при замене наименований лекарств. Снижение производительности было более заметным в наборе данных MedMCQA, чем в MedQA, при этом MedMCQA показал среднее снижение точности на 4%. Исследователи выявили загрязнение набора данных как потенциальный источник этой хрупкости, отметив, что наборы данных предварительного обучения содержали значительные тестовые данные для оценки.
Выводы
Данное исследование подчеркивает критическую проблему в биомедицинской NLP: хрупкость языковых моделей в отношении вариаций наименований лекарств. Представляя набор данных RABBITS, исследовательская группа предоставила ценный инструмент для оценки и улучшения устойчивости языковых моделей в обработке медицинской терминологии. Эта работа подчеркивает важность разработки NLP систем, которые являются устойчивыми, контекстно-ориентированными и способными предоставлять точную медицинскую информацию независимо от вариаций в терминологии. Развитие таких систем необходимо для обеспечения надежной и точной обработки медицинской информации, в конечном итоге приводящей к лучшим результатам для пациентов и более эффективной предоставлению медицинской помощи.
Подробнее о данном исследовании и результаты можно узнать по ссылке Paper.
Для обсуждения возможности применения искусственного интеллекта в вашем бизнесе обращайтесь в наш Телеграм-канал t.me/itinainews.
«`

















