
Введение в улучшение больших языковых моделей
Недавние исследования в области обучения с подкреплением (RL) показывают, что эти методы могут значительно улучшить большие языковые модели (LLMs) по сравнению с традиционными методами обучения. RL позволяет моделям учиться оптимальным ответам через сигналы вознаграждения, что улучшает их способность к рассуждению и принятию решений.
Проблемы и вызовы
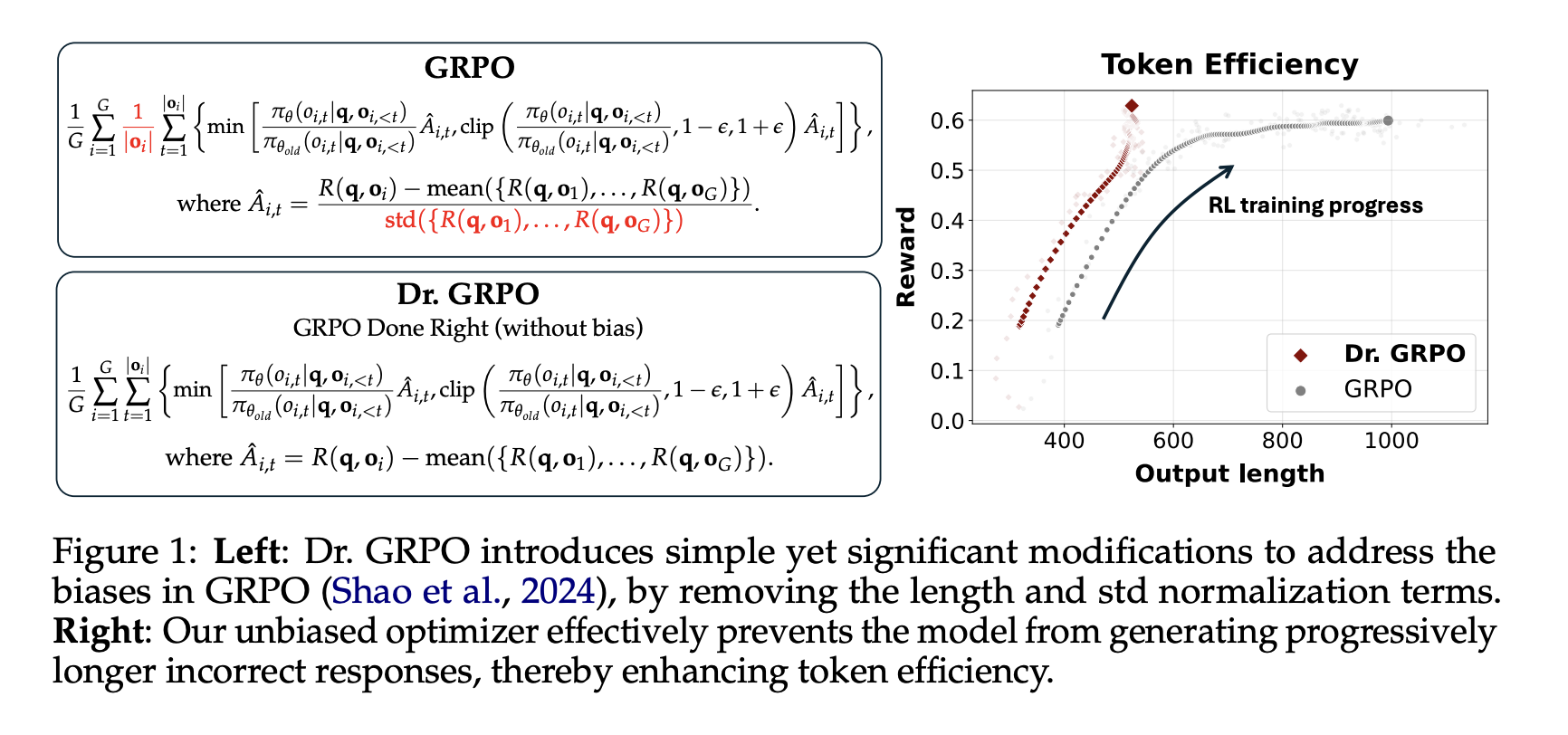
Одна из главных задач в улучшении LLMs — это развитие их мыслительных способностей, а не просто увеличение длины ответов. В процессе обучения RL модели иногда начинают генерировать слишком длинные ответы, не улучшая качество. Это поднимает вопросы об оптимизационных предвзятостях в методах RL, которые могут поощрять многословие.
Новые подходы и решения
Исследователи из Sea AI Lab, Национального университета Сингапура и Университета менеджмента Сингапура представили новый подход, названный Dr. GRPO, который устраняет ненужные нормализации в алгоритме GRPO. Этот метод обеспечивает более справедливые обновления модели, что ведет к лучшим результатам.
Результаты и достижения
Модель Qwen2.5-Math-7B, обученная с использованием метода Dr. GRPO, показала следующие результаты:
- 43.3% на AIME 2024
- 62.7% на OlympiadBench
- 45.8% на Minerva Math
- 40.9% на MATH500
Это подтверждает эффективность метода без предвзятостей. Модель также демонстрировала более эффективное использование токенов, делая неправильные ответы короче и более сосредоточенными.
Ключевые выводы
- Модели DeepSeek-V3-Base и Qwen2.5 показывают способности рассуждения даже до RL, что подчеркивает важность предварительного обучения.
- Dr. GRPO устраняет предвзятости в GRPO, улучшая эффективность токенов.
- Модели, обученные по меньшим наборам вопросов, иногда показывают лучшие результаты, чем те, что обучены на больших датасетах.
Заключение
Данное исследование подчеркивает, как RL может изменить поведение LLM. Важно фокусироваться на прозрачности методов и характеристиках базовых моделей, а не только на производительности. Новые подходы, такие как Dr. GRPO, открывают новые горизонты в обучении моделей и могут значительно повлиять на будущее технологий.
Практическое применение ИИ в бизнесе
Исследуйте, как технологии искусственного интеллекта могут трансформировать ваш подход к работе:
- Автоматизация процессов в вашей компании.
- Определение ключевых показателей эффективности (KPI) для оценки влияния ИИ на бизнес.
- Выбор инструментов, соответствующих вашим потребностям.
- Запуск небольших проектов, сбор данных и постепенное расширение применения ИИ.
Для получения консультаций по внедрению ИИ в бизнес, свяжитесь с нами по адресу hello@itinai.ru.
Следите за новостями ИИ, подписавшись на наш Telegram.
Посмотрите практическое решение с использованием ИИ: продажный бот, предназначенный для автоматизации взаимодействия с клиентами.




















