
«`html
Современные ИИ-системы и их адаптация
Современные ИИ-системы используют методы, такие как супервизорная дообучение (SFT) и обучение с подкреплением (RL), чтобы адаптировать базовые модели для конкретных задач. Важно понимать, помогают ли эти методы моделям запоминать данные обучения или обобщать для новых сценариев. Это различие критично для создания надежных ИИ-систем, способных справляться с реальными изменениями.
Риски и возможности методов SFT и RL
Ранее проведенные исследования показывают, что SFT может привести к переобучению, из-за чего модели становятся менее устойчивыми к новым задачам. Например, модель, обученная с помощью SFT, может успешно решать арифметические задачи, но провалиться, если правила изменятся. RL, с другой стороны, может как развить гибкость в решении задач, так и укрепить узкие стратегии. Однако существующие оценки часто не различают запоминание и истинное обобщение, оставляя специалистов в неведении о том, какой метод предпочесть.
Исследование по сравнению SFT и RL
Недавнее исследование от HKU, UC Berkeley, Google DeepMind и NYU исследует, как SFT и RL влияют на способность модели адаптироваться к новым вызовам. В рамках эксперимента были разработаны две задачи: GeneralPoints (арифметическое логическое мышление) и V-IRL (визуальная навигация). Обе задачи включают как обучающие данные, так и варианты для проверки адаптивности.
Основные результаты
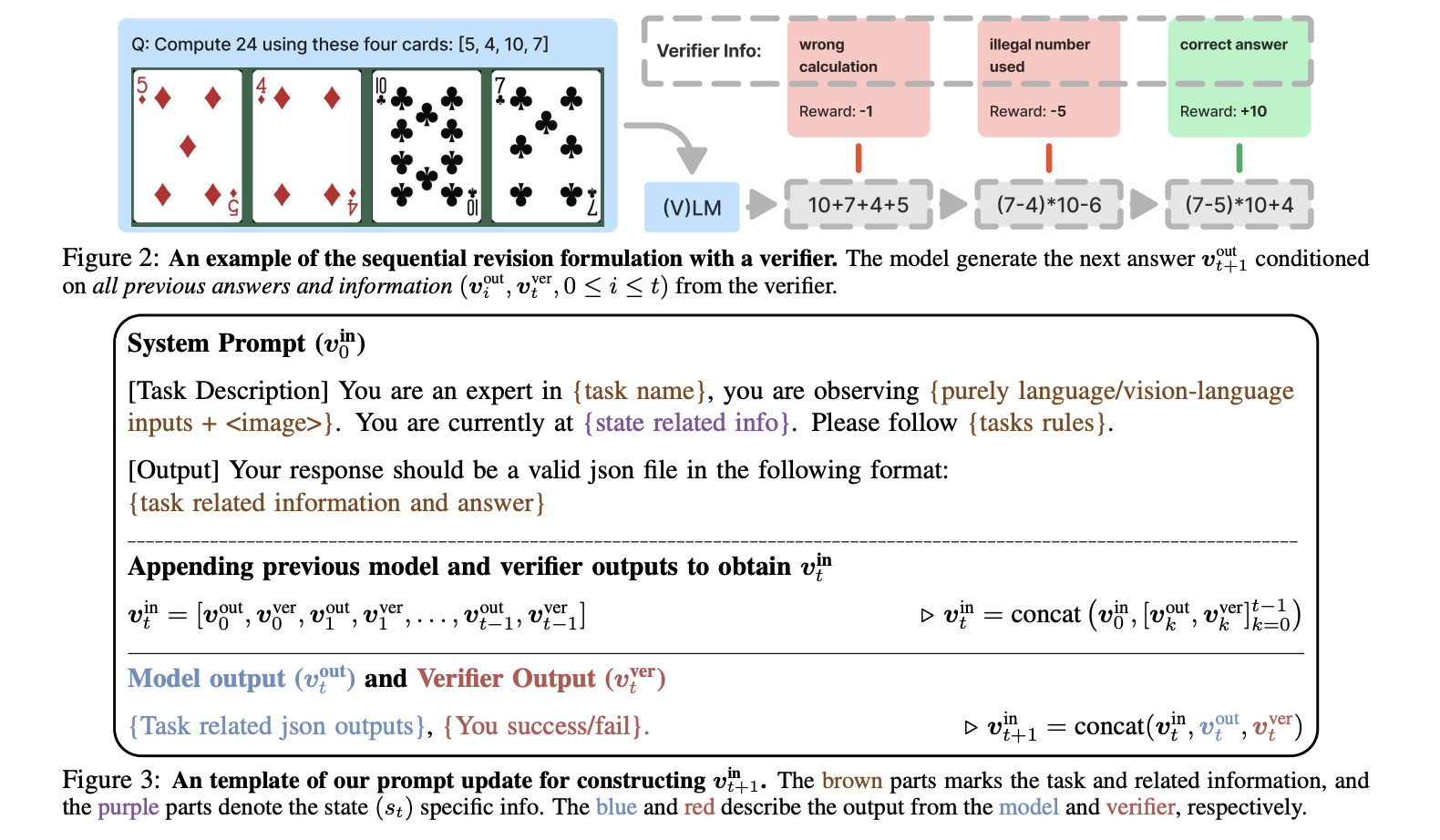
1. Арифметическое обобщение (GeneralPoints): Модели должны составить уравнения, равные 24, используя четыре числа из игральных карт. Варианты меняют правила значений карт.
2. Визуальное обобщение (V-IRL): Модели должны достичь цели, ориентируясь по визуальным маркерам. Варианты меняют способы действия и тестируют в незнакомых городах.
Сравнение методов SFT и RL
SFT тренирует модели на воспроизведение правильных ответов из помеченных данных, что приводит к запоминанию. RL, наоборот, оптимизирует для максимизации награды, что помогает моделям понимать структуру задач.
Практические выводы для специалистов
Исследование подтверждает компромисс: SFT хорошо подходит для подгонки под обучающие данные, но теряет эффективность с изменением распределения. RL, наоборот, предлагает адаптивные и обобщаемые стратегии. Специалистам следует использовать RL после SFT, но только до достижения базовой компетенции в задаче.
Рекомендации для внедрения ИИ
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые нужно улучшить с помощью ИИ.
- Используйте подходящее решение, начиная с малого проекта.
- Анализируйте результаты и данные, расширяйте автоматизацию.
Для получения советов по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем канале.
Попробуйте AI Sales Bot
Этот ИИ-ассистент помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab!
«`



















