
«`html
Direct Preference Optimization (DPO) в обучении языковых моделей
Direct Preference Optimization (DPO) — это продвинутый метод обучения для настройки больших языковых моделей (LLMs). В отличие от традиционной надзорной настройки, зависящей от одной эталонной ссылки, DPO обучает модели различать качество различных кандидатских выходов. Эта техника критически важна для согласования LLM с предпочтениями людей, улучшая их способность генерировать желаемые ответы эффективно. Путем включения методов обучения с подкреплением DPO позволяет моделям учиться на обратной связи, делая его ценным подходом в обучении языковых моделей.
Оптимизация ссылочных моделей и обучение DPO
Основная проблема, рассматриваемая в этом исследовании, касается ограничений, накладываемых переходом к ссылочным моделям или политикам в процессе DPO. Хотя они важны для поддержания стабильности и направления обучения, эти ссылки могут ограничить потенциальные улучшения производительности LLM. Понимание оптимального использования и силы этих ссылок критически важно для максимизации эффективности и качества выходных данных обученных с помощью DPO моделей.
Исследование и практические рекомендации
Текущие методы в обучении предпочтениям включают надзорную настройку (SFT), подходы к обучению с подкреплением (RL) и техники обучения на основе вознаграждения. DPO, в частности, включает ограничение KL-дивергенции для управления отклонениями от ссылочной модели. Это ограничение обеспечивает, что модель не слишком уходит от ссылки, сбалансированно следуя ссылке и оптимизируя производительность. Эти методы улучшают согласованность модели с предпочтениями людей, делая их более эффективными в генерации точных и предпочтительных выходных данных.
Исследователи из Университета Йель, Шанхайского Жао Тунского Университета и Института искусственного интеллекта Аллен представили всесторонний анализ зависимости DPO от ссылочных политик. Они изучили оптимальную силу ограничения KL-дивергенции и оценили необходимость ссылочных политик в инструктажной настройке. Исследование включало варьирование силы ограничения для определения наилучшего баланса, максимизирующего производительность DPO без чрезмерной зависимости от ссылочной модели.
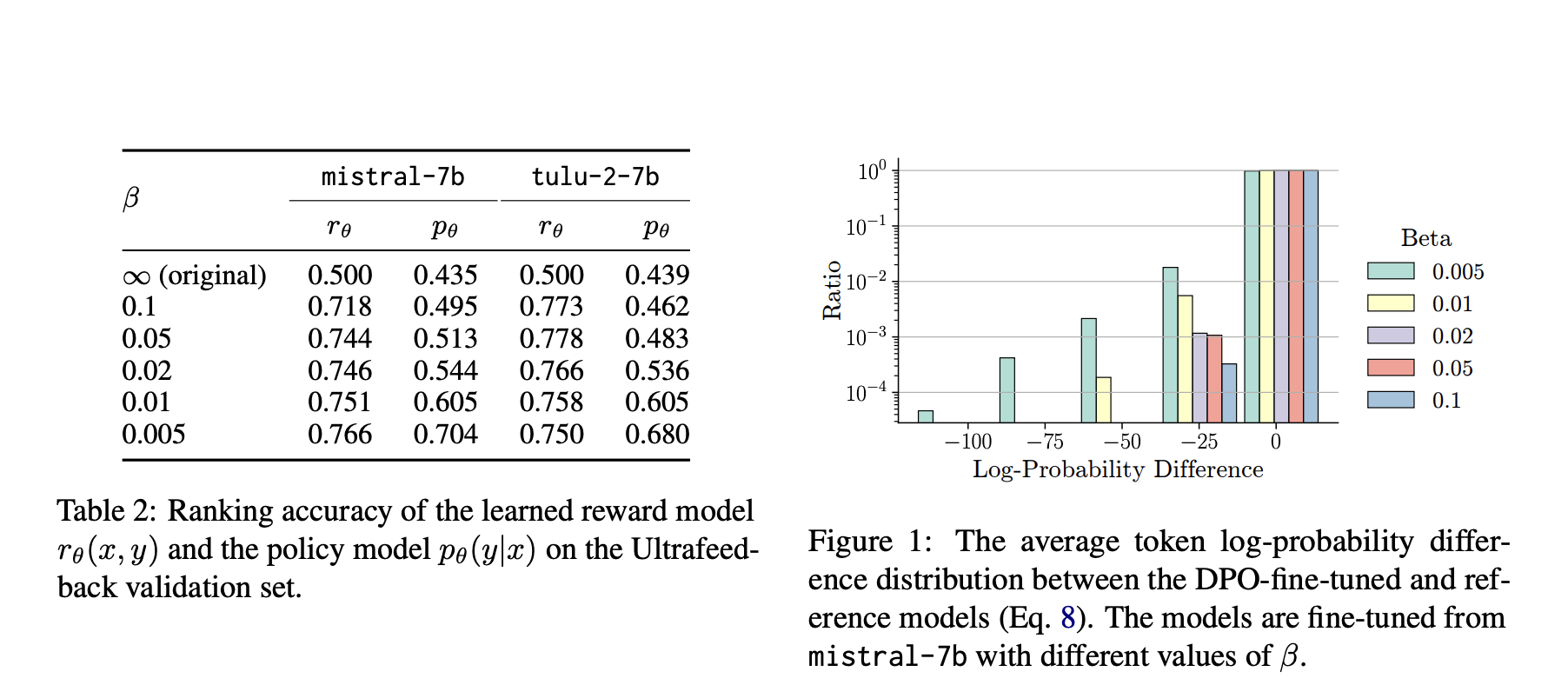
Предложенный метод включает детальное изучение различных сил ограничения KL-дивергенции, используемых в DPO. Исследователи провели эксперименты с использованием открытых предварительно обученных LLMs, Tulu 2 и Mistral, на тесте AlpacaEval. Они проанализировали производительность на уровне последовательности и уровне токена, чтобы понять, как изменение силы ограничения влияет на точность и стабильность модели. Эксперименты показали, что меньшее ограничение KL-дивергенции обычно улучшало производительность, пока оно не становилось слишком маленьким, что приводило к ухудшению. Кроме того, они изучили необходимость ссылочных политик, сравнивая DPO с альтернативными целями обучения, демонстрируя превосходство DPO при использовании подходящей ссылочной модели.
Исследование выявило значительные результаты относительно влияния ограничения KL-дивергенции на производительность DPO. Меньшее ограничение обычно приводило к лучшей производительности, с оптимальным значением β около 0,01-0,02. Например, модель, настроенная на основе Mistral-7b, достигла оценки AlpacaEval2 в 16,25 при β равном 0,01, по сравнению с исходной оценкой 7,57 без DPO. Анализ показал, что уменьшение силы ограничения улучшало производительность до тех пор, пока оно не становилось слишком маленьким, после чего производительность модели ухудшалась. Кроме того, более сильные ссылочные модели, такие как Mistral-v0.2 и Llama-3-70b, предоставляли дополнительные преимущества, но только при совместимости с настраиваемой моделью. Исследование подчеркнуло важность выбора подходящей ссылочной политики для достижения оптимальных результатов.
Исследование подчеркивает тонкую роль ссылочных политик в DPO. Путем тщательной калибровки силы ограничения и выбора совместимых ссылочных моделей исследователи могут значительно улучшить производительность LLMs. Полученные результаты подчеркивают необходимость дальнейших исследований для изучения взаимосвязи между ссылочными политиками и производительностью обучения DPO. Кроме того, исследование призывает к разработке более теоретических и эмпирических рекомендаций для лучшего понимания совместимости между обученными и ссылочными моделями. В целом, это исследование предоставляет ценные инсайты и практические рекомендации по улучшению DPO и развитию области настройки языковых моделей.
Проверьте статью и репозиторий на GitHub. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте следить за нами в Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Присоединяйтесь к нашему сообществу
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте How Important is the Reference Model in Direct Preference Optimization DPO? An Empirical Study on Optimal KL-Divergence Constraints and Necessity.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















