
Оценка модели LLM OpenAI o1 в медицине: Улучшение понимания и рассуждений в клинических контекстах
Прогресс в области искусственного интеллекта
Модели LLM значительно продвинулись, демонстрируя свои возможности в различных областях. Интеллект, как многогранный концепт, включает в себя множество когнитивных навыков, и LLM приблизили искусственный интеллект к достижению общего интеллекта. Недавние разработки, такие как модель o1 от OpenAI, интегрируют техники рассуждений, например, Chain-of-Thought (CoT) prompting, для улучшения решения проблем. В то время как o1 хорошо справляется с общими задачами, его эффективность в специализированных областях, таких как медицина, остается неопределенной.
Практические решения и ценность
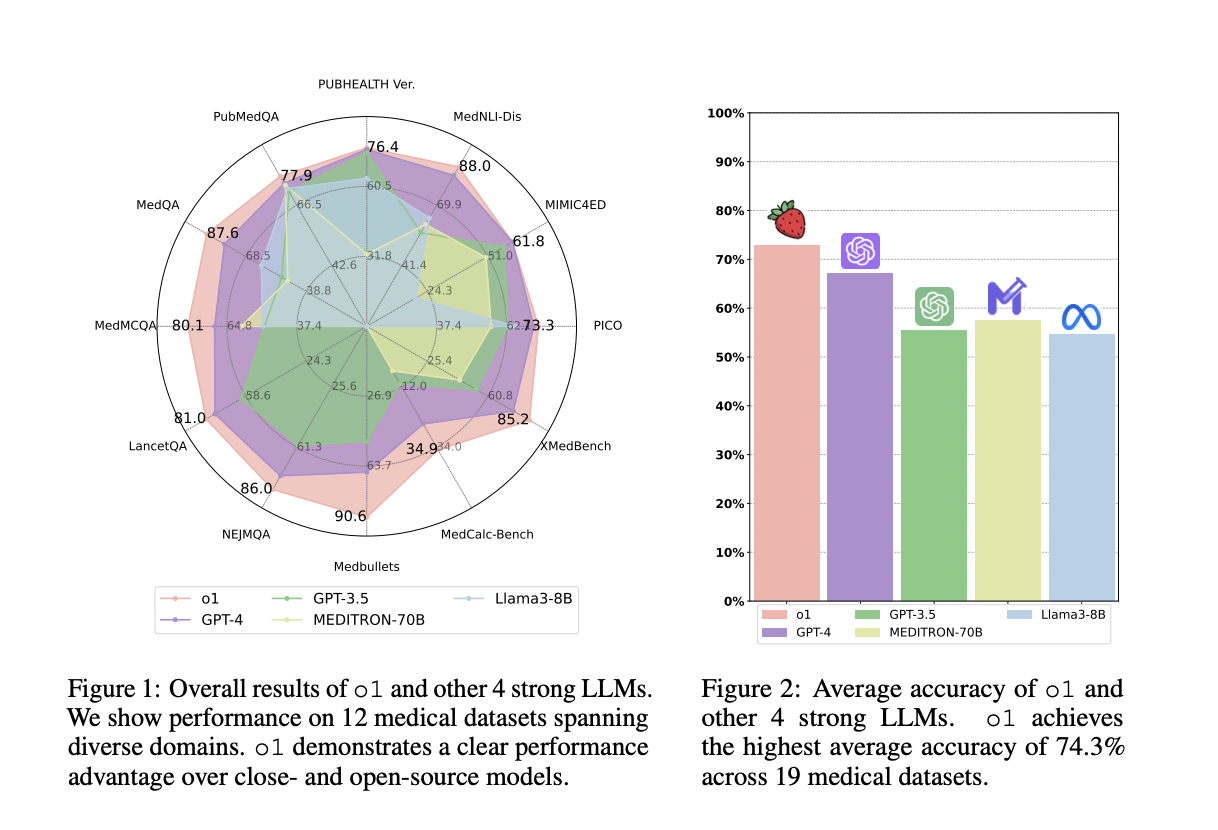
Исследователи из Университета Калифорнии в Санта-Круз, Университета Эдинбурга и Национального института здоровья оценили модель o1 от OpenAI, первую LLM, использующую техники CoT с обучением с подкреплением. Это исследование изучило производительность o1 в медицинских задачах, оценивая понимание, рассуждения и мультиязычность на 37 медицинских наборах данных, включая два новых QA бенчмарка. Модель o1 превзошла GPT-4 в точности на 6,2%, но все еще имела проблемы, такие как галлюцинации и нестабильная мультиязычная способность. Исследование подчеркивает необходимость последовательных метрик оценки и улучшенных шаблонов инструкций.
Применение в медицине и дальнейшее развитие
LLM продемонстрировали значительный прогресс в задачах понимания языка через предсказание следующего токена и тонкую настройку инструкций. Однако они часто сталкиваются с сложностями в выполнении сложных логических задач. Для преодоления этого исследователи представили CoT prompting, направляя модели на эмуляцию процессов человеческого рассуждения. Модель o1 от OpenAI, обученная на обширных данных CoT и обучении с подкреплением, нацелена на улучшение способностей к рассуждениям. Исследование исследует потенциал o1 для клинического применения, показывая улучшения в понимании, рассуждениях и мультиязычных способностях.





















