
«`html
Идентификация метафорических компонентов (MCI) в задачах обработки естественного языка (NLP)
Идентификация метафорических компонентов (MCI) – важный аспект обработки естественного языка (NLP), который включает в себя определение и интерпретацию метафорических элементов, таких как тенор, транспортное средство и основание. Эти компоненты критически важны для понимания метафор, которые широко распространены в повседневной коммуникации, литературе и научном дискурсе. Точная обработка метафор необходима для различных приложений NLP, включая анализ настроений, информационный поиск и машинный перевод. В связи с сложностью метафор и их зависимостью от контекста и фоновых знаний, MCI представляет собой уникальное испытание в вычислительной лингвистике.
Проблема MCI
Основная проблема MCI заключается в сложности и разнообразии метафор. Традиционные подходы к определению этих метафорических элементов часто оказываются недостаточными из-за своей зависимости от ручных правил и словарей, которые ограничены в области применения и адаптивности. Эти методы сталкиваются с трудностями в уловлении тонкостей метафор, особенно при понимании контекста, в котором они используются.
Решение через deep learning
В последние годы глубокое обучение предложило новые возможности для MCI. Модели нейронных сетей на основе векторных представлений слов и последовательностных моделей показали перспективы в улучшении возможностей распознавания метафор. Однако эти модели все еще сталкиваются с трудностями в контекстуальном понимании и обобщении. В связи с этим существует потребность в более продвинутых методах, способных эффективно решать эти проблемы и повышать точность MCI.
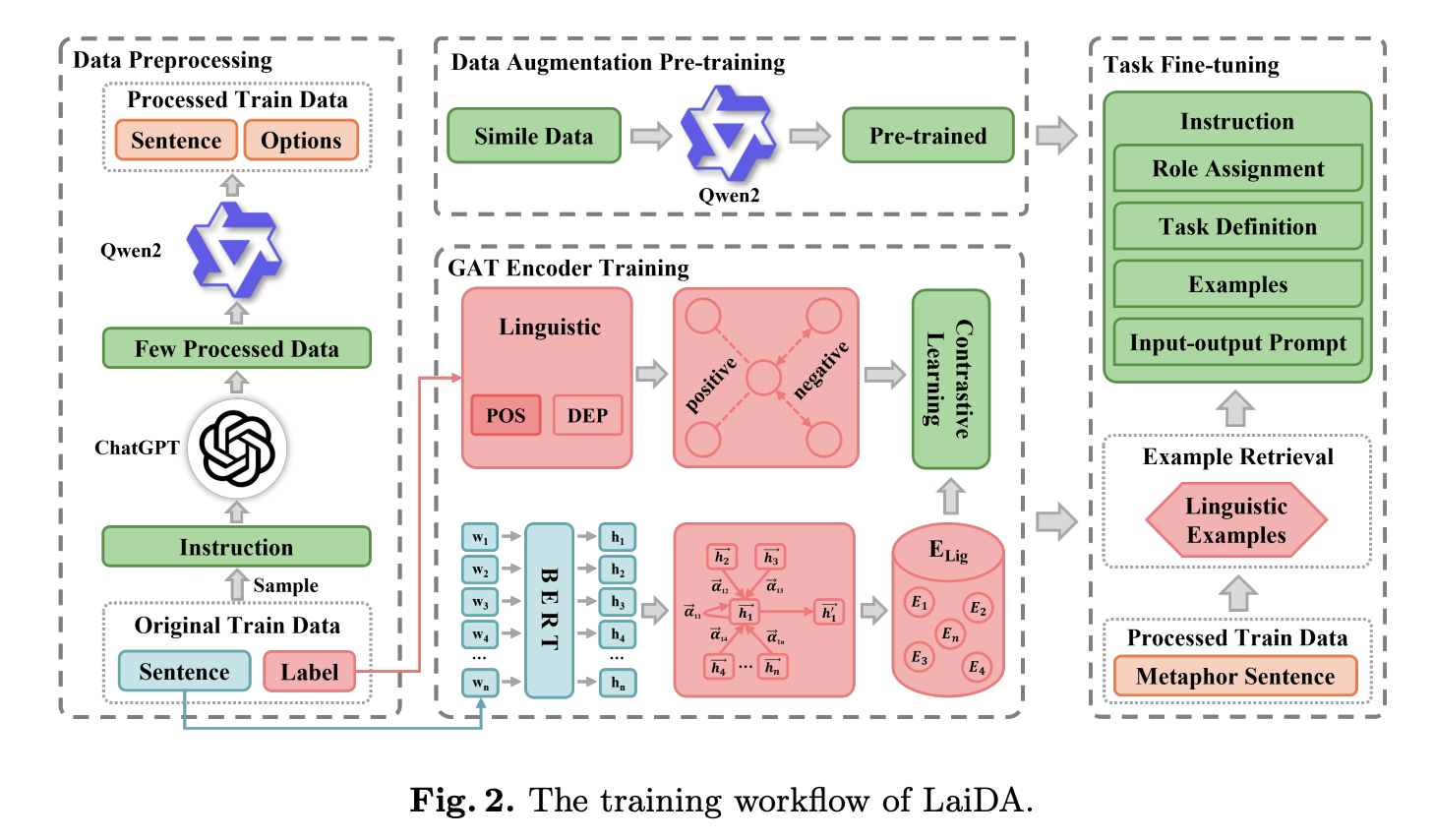
Инновационный подход LaiDA
Исследователи из Университета Чжэнчжоу представили новую концепцию под названием Linguistics-aware In-context Learning with Data Augmentation (LaiDA). Этот подход использует мощь больших языковых моделей (LLM), таких как ChatGPT, для улучшения точности и эффективности MCI. LaiDA интегрирует контекстное обучение с методами увеличения данных для создания более надежного и адаптивного метода распознавания метафор. Путем включения лингвистически схожих примеров в процесс дообучения LaiDA улучшает способность модели понимать и обрабатывать сложные метафоры.
Результаты и перспективы
В ходе исследования была достигнута замечательная точность 93,21% в рамках NLPCC2024 Shared Task 9, занимая второе место в общем рейтинге. LaiDA проявила особую силу в определении компонентов метафор – тенора и транспортного средства, достигнув точности 97,20% и 97,32% соответственно. Однако точность определения основания была немного ниже и составила 94,14%, что подчеркивает увеличенную сложность в улавливании этого аспекта метафор. Применение LaiDA также привело к увеличению точности на 0,9% при включении модуля предварительного обучения с увеличением данных и на 2,6% при использовании контекстного обучения. Эти результаты подчеркивают значительное влияние инновационного подхода LaiDA к MCI.
Заключение и рекомендации
Исследовательская команда Университета Чжэнчжоу внесла значительный вклад в область MCI с введением LaiDA. Путем объединения лингвистически осознанного контекстного обучения с увеличением данных LaiDA предлагает мощный инструмент для улучшения точности и эффективности распознавания метафор в задачах NLP. Способность фреймворка интегрировать лингвистически схожие примеры в процессе дообучения и использование продвинутых LLM и кодировщика GAT устанавливают новый стандарт в этой области. Успех LaiDA в рамках NLPCC2024 Shared Task 9 дополнительно подтверждает его эффективность, делая его ценным ресурсом для специалистов, работающих над идентификацией и интерпретацией метафор.
Подробнее о работе можно узнать в статье и на GitHub. Вся заслуга за это исследование принадлежит ученым этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Ученые из AI-центра FPT Software представляют XMainframe: современную крупномасштабную языковую модель (LLM), специализированную для модернизации легаси-кода, чтобы решить проблему модернизации наследственного кода на сумму $100 млрд.
Источник: MarkTechPost.