
«`html
Retrieval Augmented Generation (RAG) and Multi-Head RAG (MRAG)
Retrieval Augmented Generation (RAG) — метод, который улучшает возможности больших языковых моделей (LLM), интегрируя систему извлечения документов. Это позволяет LLM извлекать актуальную информацию из внешних источников, повышая точность и релевантность сгенерированных ответов.
Применение в различных отраслях
В различных отраслях возникают запросы, требующие извлечения информации из нескольких документов с разнообразным содержанием. Например, при анализе аварий на химических заводах необходимо получать данные из документов, касающихся обслуживания оборудования, погодных условий и управления персоналом.
Недостатки существующих решений
Существующие решения RAG часто испытывают сложности с точностью извлечения при многоаспектных запросах, что приводит к необходимости улучшения релевантности полученных данных.
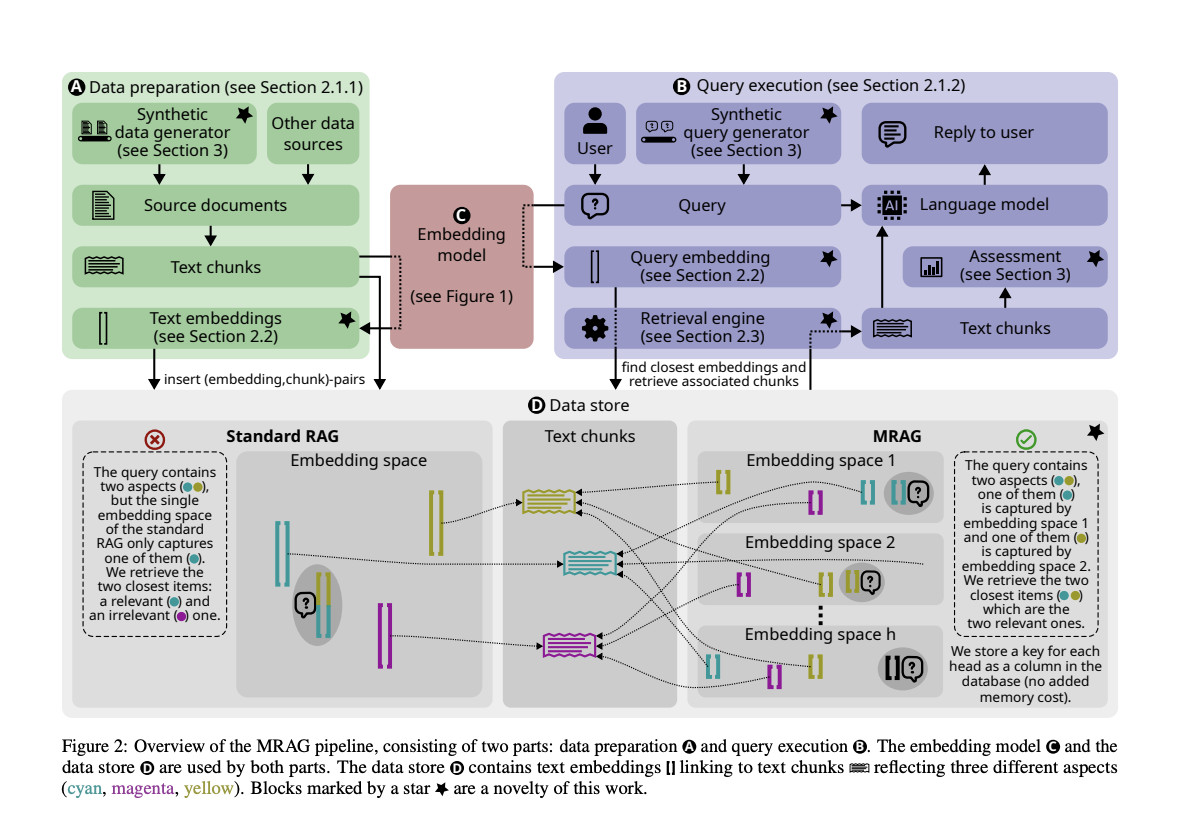
Решение — Multi-Head RAG (MRAG)
MRAG использует активации из многоголового слоя внимания модели Transformer, чтобы улучшить точность извлечения при многоаспектных запросах. Это позволяет создавать вложения, представляющие различные аспекты данных, улучшая способность системы извлекать актуальную информацию из разнообразных областей содержания.
Преимущества MRAG
MRAG значительно улучшает релевантность извлечения, демонстрируя до 20% лучшую производительность по сравнению со стандартными базовыми решениями RAG при извлечении многоаспектных документов.
Эффективность и практичность
MRAG эффективен и энергоэффективен, не требуя дополнительных запросов LLM, увеличенного хранилища или множественных проходов по модели вложений. Это позиционирует MRAG как ценное достижение в области LLM и систем RAG.
Заключение
MRAG представляет собой значительное достижение в области RAG, обеспечивая более точное и эффективное решение для извлечения информации из сложных документов. Это открывает путь к более надежным и актуальным результатам от LLM, что приносит пользу различным отраслям, требующим комплексных возможностей извлечения данных.
Подробнее ознакомьтесь с исследованием.
Авторы исследования: [researchers]
Следите за нами в Twitter.
Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Подпишитесь на нашу рассылку.
Присоединяйтесь к нашему сообществу в Reddit.
«`
















