
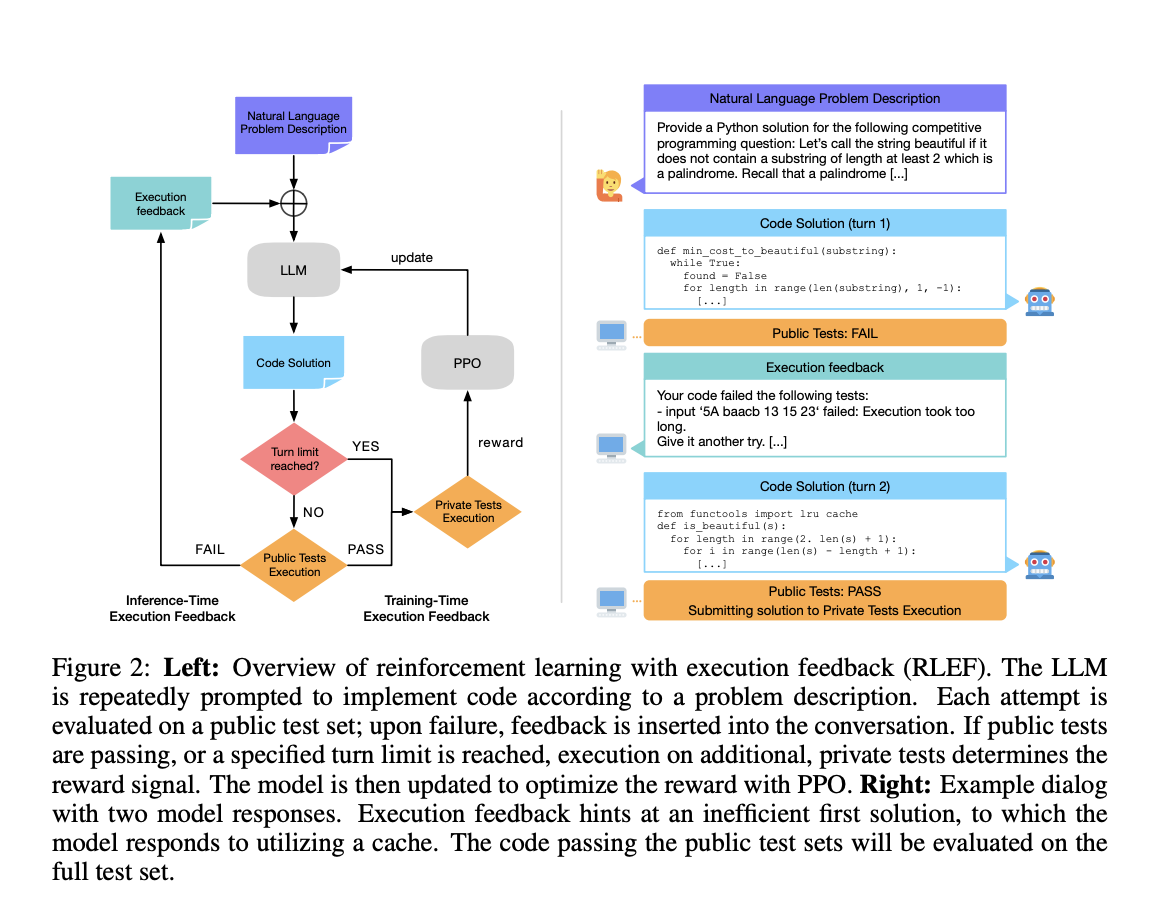
Решение проблемы генерации кода с помощью усиленного обучения и обратной связи выполнения
Проблема:
Большие языковые модели (LLM) генерируют код с помощью обработки естественного языка. Однако выравнивание с входными данными требует много времени и ресурсов.
Решение:
Внедрение усиленного обучения и обратной связи выполнения (RLEF) позволяет моделям улучшать себя, предоставляя реальную обратную связь в режиме реального времени.
Преимущества:
1. Улучшение производительности моделей при ограниченном количестве обучающих ситуаций.
2. Увеличение эффективности обработки многоходовых разговоров.
3. Снижение времени вычислений и уровня ошибок.
Результаты:
Использование RLEF позволяет преодолеть ограничения обучения с учителем, обеспечивая эффективное и адаптивное кодирование для разработки программного обеспечения.




















