
Расшифровка моделей языков трансформера: прогресс в исследованиях интерпретируемости
Возникновение мощных языковых моделей на основе трансформеров подчеркивает необходимость исследования их внутренних механизмов. Понимание этих механизмов в передовых системах искусственного интеллекта (ИИ) критично для обеспечения их безопасности, справедливости и минимизации предвзятости и ошибок, особенно в критических контекстах. В результате наблюдается значительный рост исследований в области обработки естественного языка (NLP), нацеленных на интерпретируемость языковых моделей, что приводит к новым пониманиям их внутренних операций.
Технический обзор методов интерпретируемости моделей
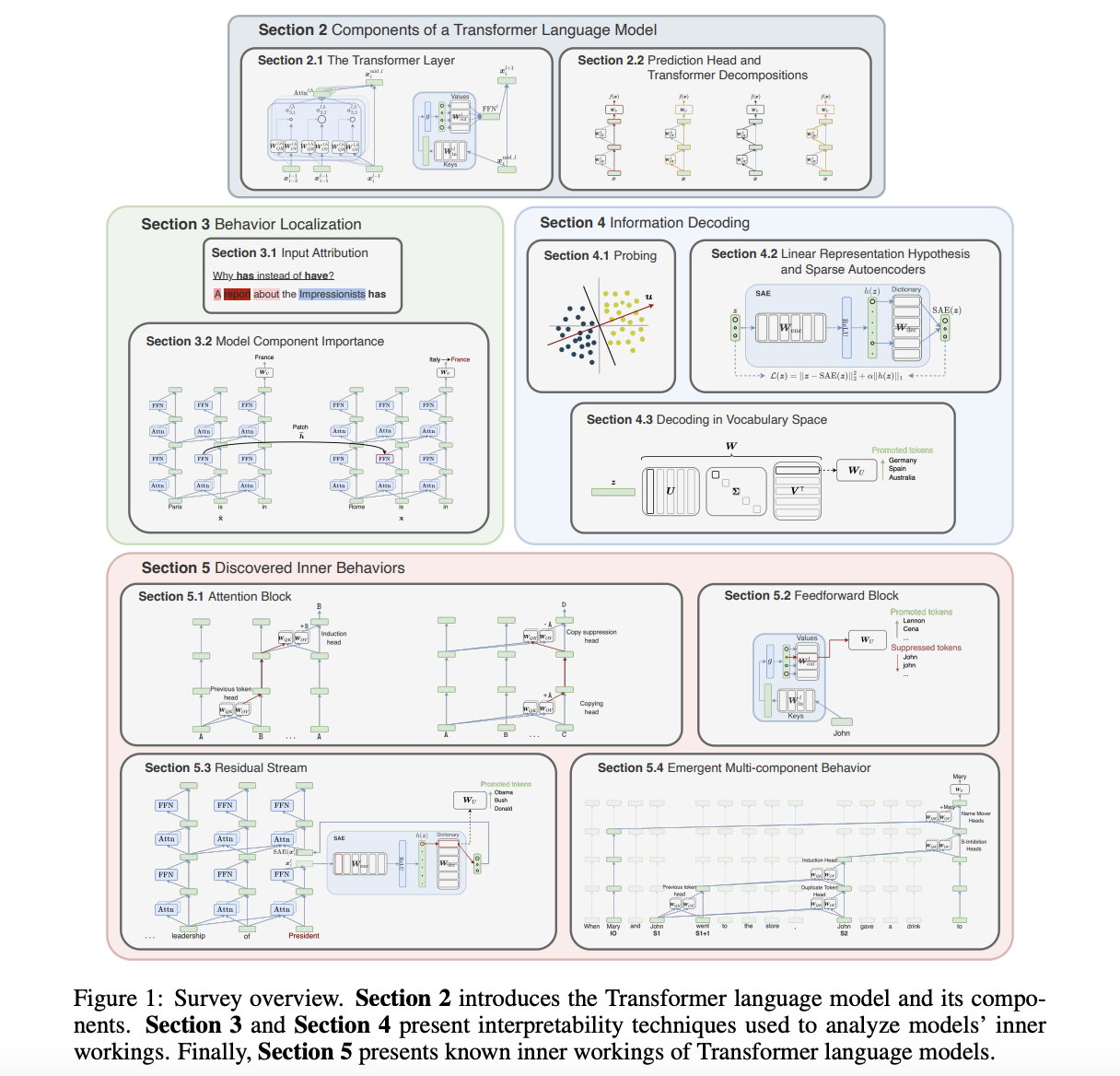
Исследователи из Universitat Politècnica de Catalunya, CLCG, University of Groningen и FAIR, Meta представляют исследование, которое предлагает подробный технический обзор методов, используемых в исследованиях интерпретируемости языковых моделей. Они выделяют компоненты моделей, методы интерпретируемости и приводят перспективные инсайты, обосновывая конкретные методы. Подходы к интерпретируемости языковых моделей категоризированы на основе двух измерений: локализация входов или компонентов модели для предсказаний и декодирование информации в обученных представлениях.
Методы интерпретируемости
Исследователи представляют два типа методов, позволяющих локализовать поведение модели: методы атрибуции входа и атрибуции компонента модели. Методы атрибуции входа оценивают важность токенов с использованием градиентов или возмущений. Альтернативы смешивания контекста для весов внимания предоставляют инсайты в атрибуции токенов. Атрибуция логита измеряет вклад компонентов, а причинные вмешательства рассматривают вычисления как причинные модели. Анализ цепей идентифицирует взаимодействующие компоненты, современные подходы автоматизируют поиск цепей и абстрагируют причинные отношения.
Декодирование информации в моделях нейронных сетей
Исследователи также изучают методы декодирования информации в моделях нейронных сетей, особенно в обработке естественного языка. Они описывают использование пробы для предсказания свойств ввода из промежуточных представлений, линейные вмешательства, разреженные автокодировщики и улучшенные функции обнаружения признаков. Также предоставляют обзор нескольких библиотек с открытым исходным кодом, предназначенных для упрощения исследований интерпретируемости на основе трансформеров.
Заключение
Это исследование подчеркивает важность понимания внутренних механизмов языковых моделей на основе трансформеров для обеспечения их безопасности, справедливости и уменьшения предвзятости. Путем подробного изучения методов интерпретируемости и полученных инсайтов исследование вносит значительный вклад в развивающуюся область интерпретируемости ИИ. Путем категоризации методов интерпретируемости и демонстрации их практических применений исследование продвигает понимание области и облегчает усилия по улучшению прозрачности и взаимодействия моделей.