
Усовершенствование стабильности и производительности крупных языковых моделей с помощью фреймворка надежного обучения с подкреплением от обратной связи человека
Основные моменты:
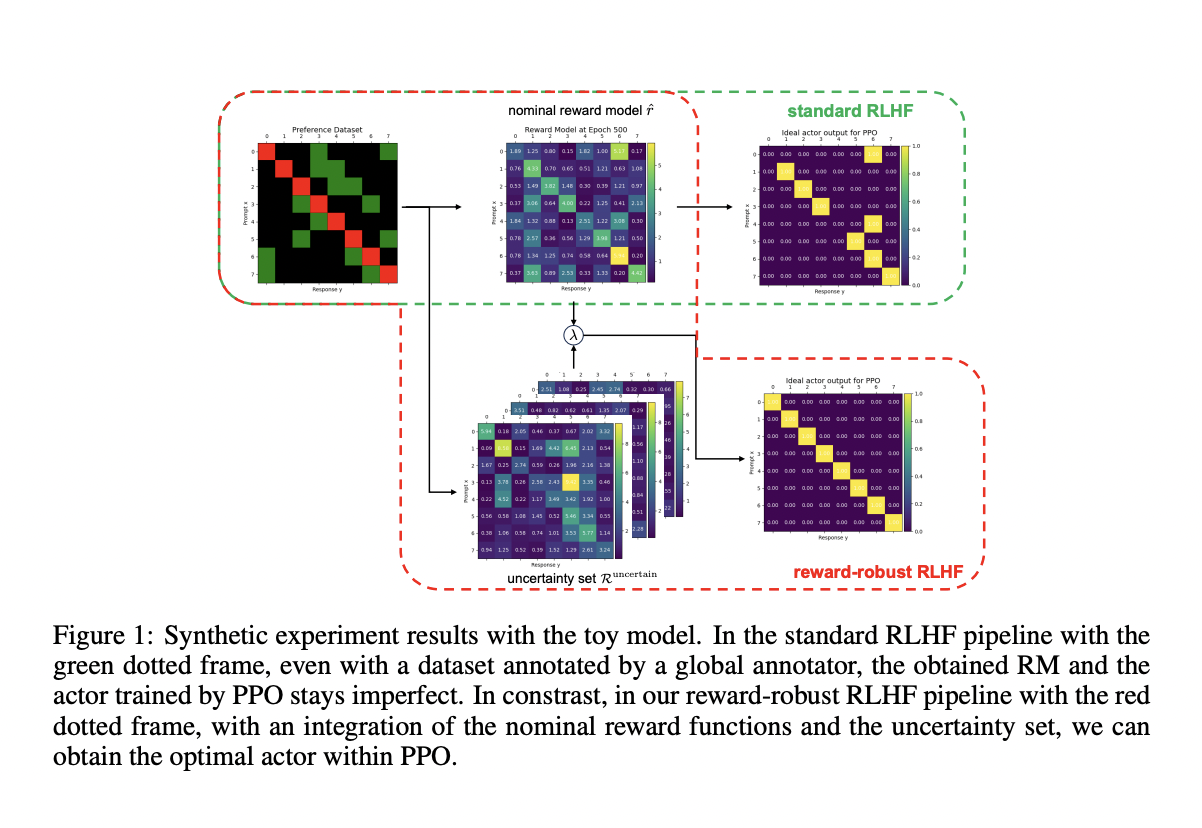
Фреймворк RLHF значительно улучшает способности языковых моделей, обучая их на основе обратной связи, что позволяет создавать более полезные, безопасные и честные результаты.
Методика включает в себя использование ансамблей байесовских моделей вознаграждения для эффективного управления неопределенностью в сигналах вознаграждения.
Этот фреймворк демонстрирует высокую производительность, превосходя традиционные методы, и показывает стабильное улучшение в различных областях.
Практическое применение:
Используйте этот фреймворк для повышения надежности и производительности ваших языковых моделей.
Интегрируйте ансамбли моделей вознаграждения, чтобы снизить риск несоответствия и нестабильности в обучении моделей.
Получите стабильные результаты и улучшите производительность на различных задачах, демонстрируя способность фреймворка эффективно работать с несовершенными и предвзятыми данными.





















