
«`html
Исследование ИИ-исследователей MIT разбирает сложности обучения языковых моделей забывать: исследования по рандомизированной донастройке
Модели языка (LM) привлекли значительное внимание в последние годы благодаря своим удивительным способностям. Во время обучения этих моделей, нейронные последовательностные модели сначала предварительно обучаются на большом, минимально отфильтрованном веб-тексте, а затем донастраиваются с использованием конкретных примеров и обратной связи от людей. Однако эти модели часто обладают нежелательными навыками или знаниями, которые создатели хотели бы удалить перед развертыванием. Основная проблема заключается в эффективном «забывании» или удалении конкретных потенциалов без потери общей производительности модели. В то время как недавние исследования сосредоточились на разработке техник удаления целевых навыков и знаний из LM, оценка того, как это «забывание» обобщается на другие входы, остается ограниченной.
Практические решения и ценность
Существующие попытки решить проблему машинного «забывания» развиваются от предыдущих методов, сосредоточенных на удалении нежелательных данных из наборов обучающихся данных, к более продвинутым техникам. К ним относятся техники, основанные на оптимизации, редактирование модели с использованием оценки важности параметров и градиентное восхождение на нежелательные ответы. Некоторые методы включают фреймворки для сравнения забытых сетей с полностью переобученными, в то время как некоторые методы специфичны для больших языковых моделей (LLM), таких как подстрекательство к дезинформации или манипуляция представлениями модели. Однако большинство этих подходов имеют ограничения в целесообразности, обобщении или применимости к сложным моделям, таким как LLM.
Исследователи из MIT предложили новый подход к изучению поведения обобщения в забывании навыков в LMs. Этот метод включает донастройку моделей на случайно размеченных данных для целевых задач, простую, но эффективную технику для вызывания забывания. Эксперименты проводятся для характеристики обобщения забывания и выявления нескольких ключевых результатов. Подход подчеркивает характер забывания в LMs и сложности эффективного удаления нежелательных потенциалов из этих систем.
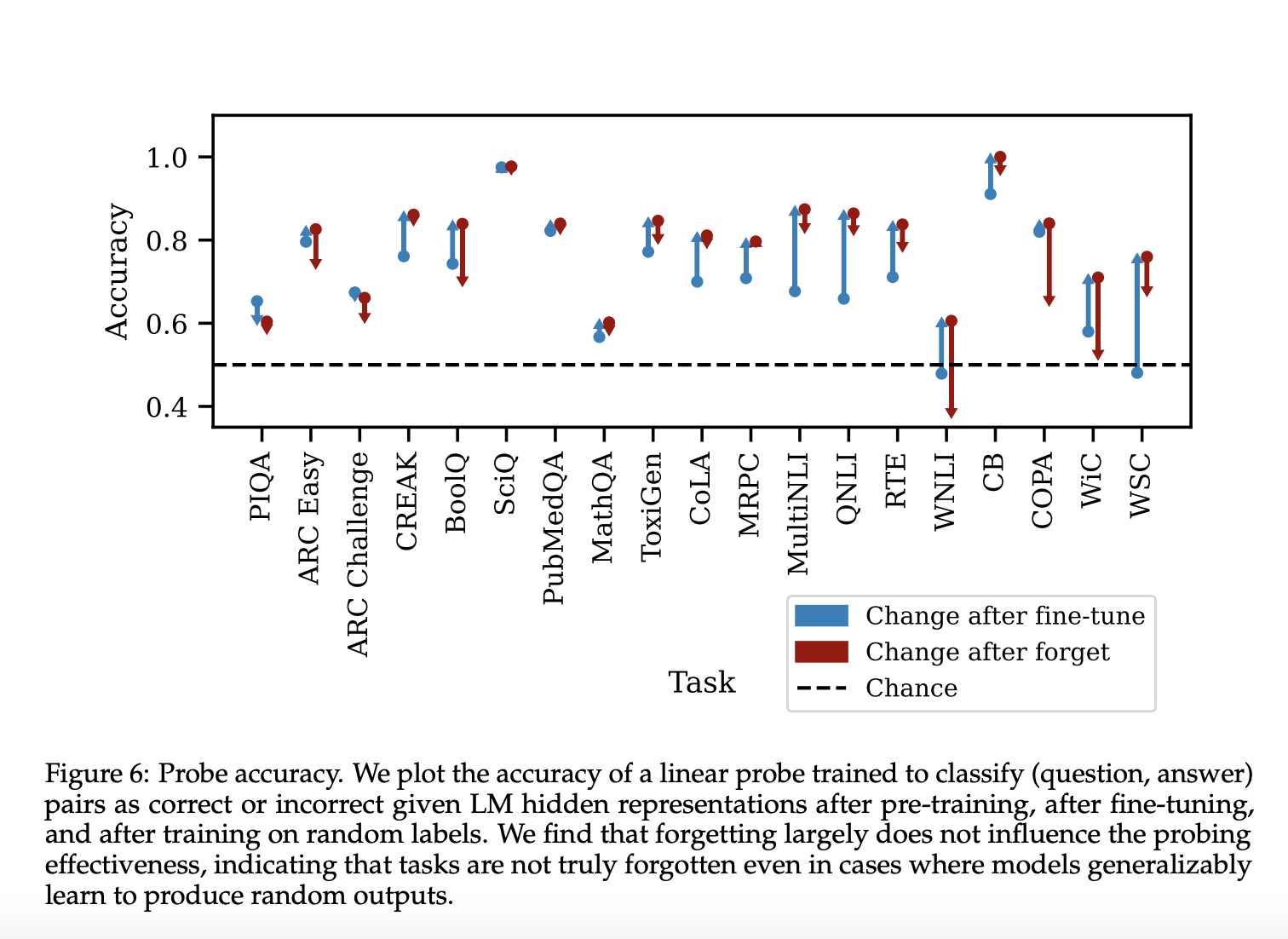
Используется комплексная система оценки, включающая 21 множественный выбор задач по различным областям, таким как здравый смысл, понимание текста, математика, токсичность и понимание языка. Эти задачи выбраны таким образом, чтобы охватить широкий спектр возможностей, сохраняя при этом последовательный формат множественного выбора. Процесс оценки следует стандартам оценки языковой модели (LMEH) для оценки с нулевой заготовкой, используя стандартные подсказки и оценку вероятностей выбора. Задачи бинаризованы, и предпринимаются шаги по очистке наборов данных путем удаления перекрытий между обучающимся и тестовыми данными и ограничения размеров выборки для сохранения последовательности. В основном эксперименты используют базовую модель Llama2 7-B параметров, обеспечивающую надежную основу для анализа поведения забывания.
Результаты показывают разнообразное поведение забывания в различных задачах. После донастройки точность теста увеличивается, хотя она может немного уменьшиться, поскольку набор проверки не идентичен набору теста. Фаза забывания производит три различные категории поведения:
- Точность забывания очень похожа на точность донастройки.
- Точность забывания уменьшается, но все равно остается выше точности предварительного обучения.
- Точность забывания уменьшается до уровня ниже точности предварительного обучения и, возможно, обратно до 50%.
Эти результаты подчеркивают сложную природу забывания в LMs и зависящую от задач природу обобщения забывания.
В заключение, исследователи из MIT предложили подход для изучения поведения обобщения в забывании навыков в LMs. В данной статье подчеркивается эффективность донастройки LMs на случайные ответы для вызывания забывания конкретных способностей. Оценочные задачи определяют степень забывания, и факторы, такие как сложность набора данных и уверенность модели, не предсказывают, насколько хорошо происходит забывание. Тем не менее, полная вариация скрытых состояний модели коррелирует с успехом забывания. Будущие исследования должны стремиться понять, почему определенные примеры забываются в задачах, и изучить механизмы процесса забывания.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и LinkedIn. Присоединяйтесь к нашему Телеграм-каналу.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 50k+ ML SubReddit.
LG AI Research Open-Sources EXAONE 3.0: A 7.8B Bilingual Language Model Excelling in English and Korean with Top Performance in Real-World Applications and Complex Reasoning
The post This AI Paper from MIT Explores the Complexities of Teaching Language Models to Forget: Insights from Randomized Fine-Tuning appeared first on MarkTechPost.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This AI Paper from MIT Explores the Complexities of Teaching Language Models to Forget: Insights from Randomized Fine-Tuning.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















