
«`html
Разгадывая модели видео-языка: глубокое исследование
Модели видео-языка (VLM), способные обрабатывать как изображения, так и текст, приобрели огромную популярность благодаря своей универсальности в решении широкого круга задач, от поиска информации в отсканированных документах до генерации кода по скриншотам. Однако развитие этих мощных моделей затрудняется недостаточным пониманием критических проектных решений, которые действительно влияют на их производительность. Этот пробел в знаниях затрудняет исследователям делать значимый прогресс в этой области. Для решения этой проблемы команда исследователей из Hugging Face и Sorbonne Université провела обширные эксперименты для выявления наиболее важных факторов при построении моделей видео-языка, сосредотачиваясь на архитектуре модели, процедурах мультимодального обучения и их влиянии на производительность и эффективность.
Текущее состояние моделей VLM
Современные модели VLM обычно используют предварительно обученные одномодальные модели, такие как большие языковые модели и кодировщики изображений, и объединяют их с помощью различных архитектурных решений. Однако исследователи отметили, что эти проектные решения часто принимаются без должного обоснования, что приводит к недопониманию их влияния на производительность. Для прояснения этого вопроса они сравнили различные архитектуры моделей, включая кросс-внимание и полностью авторегрессивные архитектуры, а также влияние замораживания или размораживания предварительно обученных основных блоков во время обучения.
Мультимодальная процедура обучения и эффективность
Исследователи также изучили процедуры мультимодального обучения, исследуя стратегии, такие как обучение пулинга для уменьшения количества визуальных токенов, сохранение исходного соотношения сторон и разрешения изображения, и разделение изображения для обмена вычислительных мощностей на производительность. Путем тщательной оценки этих проектных решений в контролируемой среде они стремились извлечь экспериментальные результаты, которые могли бы направлять разработку более эффективных и эффективных моделей VLM.
Ключевые аспекты и результаты
Одним из ключевых аспектов, изученных исследователями, был выбор предварительно обученных основных блоков для видео и языковых компонентов. Они обнаружили, что для фиксированного количества параметров качество основного блока языковой модели оказывает более значительное влияние на производительность конечной модели VLM, чем качество визионного основного блока.
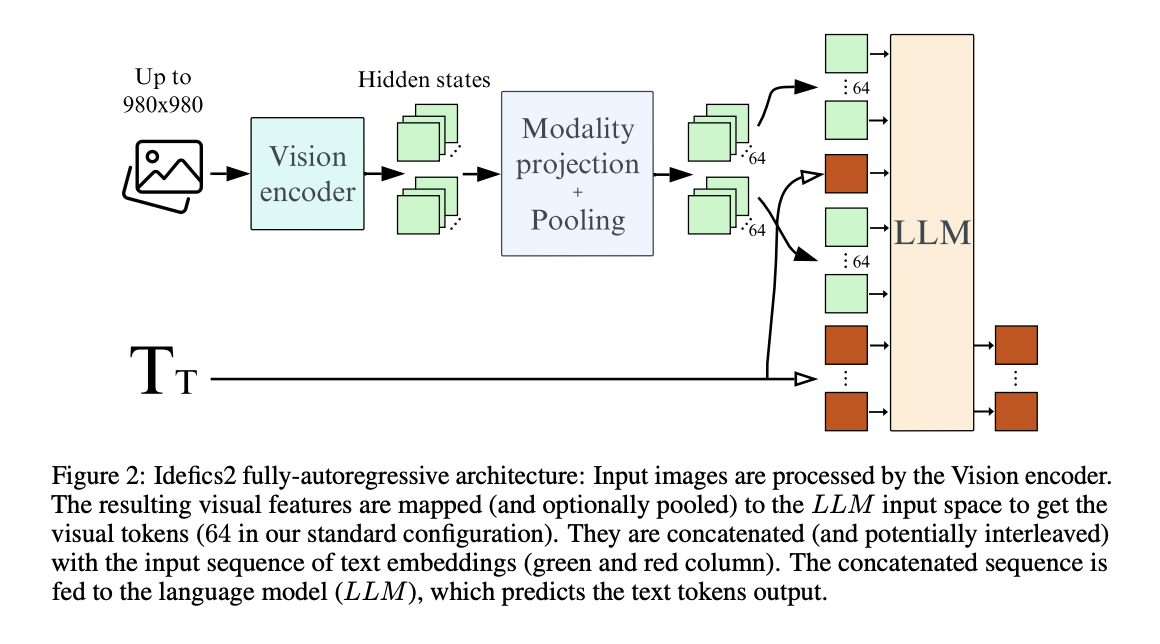
Исследователи также сравнили кросс-внимание и полностью авторегрессивные архитектуры, два распространенных выбора в проектировании VLM. В то время как архитектура кросс-внимания изначально показывала лучшие результаты, когда предварительно обученные основные блоки были заморожены, полностью авторегрессивная архитектура превзошла ее, когда предварительно обученные основные блоки были разрешены адаптироваться во время обучения.
Для повышения эффективности исследователи изучили использование обученного пулинга для уменьшения количества визуальных токенов, необходимых для каждого изображения. Эта стратегия улучшила производительность на последующих задачах и значительно снизила вычислительные затраты во время обучения и вывода.
Для практической реализации этих результатов исследователи обучили Idefics2, открытую 8-миллиардную параметрическую основную модель видео-языка. Idefics2 была обучена с использованием многоступенчатого предварительного обучения, начиная с предварительно обученных моделей SigLIP-SO400M и Mistral-7B. Она была обучена на разнообразных источниках данных, включая переплетенные изображения-текстовые документы из OBELICS, пары изображений-текста из PMD и LAION COCO, а также PDF-документы из OCR-IDL, PDFA и Rendered Text.
Исследователи оценили производительность своих предложенных методов и проектных решений с использованием различных наборов данных, включая VQAv2, TextVQA, OKVQA и COCO. Общие результаты показали, что разделение изображений на подизображения во время обучения позволило обменять вычислительную эффективность на улучшенную производительность во время вывода, особенно в задачах, связанных с чтением текста на изображении.
Количественные результаты показали, что их подход превзошел современные модели VLM в той же категории размеров, достигнув впечатляющей производительности на таких бенчмарках, как MMMU, MathVista, TextVQA и MMBench. Идефикс2 продемонстрировала производительность на уровне моделей в четыре раза большего размера и даже соответствовала производительности закрытых моделей, таких как Gemini 1.5 Pro, на нескольких бенчмарках.
Эти результаты показывают, что Idefics2 демонстрирует передовую производительность, сохраняя вычислительную эффективность во время вывода, что подтверждает эффективность подхода исследователей в построении мощных и эффективных моделей VLM путем обоснованных проектных решений.
Хотя исследователи добились значительных успехов в понимании критических факторов в разработке VLM, вероятно, существуют дополнительные возможности для улучшения и исследования. Поскольку область продолжает развиваться, их работа служит прочным фундаментом для будущих исследований и прогресса в моделировании видео-языка. Исследователи также выпустили свой набор данных для обучения, The Cauldron, массовую коллекцию из 50 наборов данных видео-языка. Открыв свою работу для общественности, включая модель, результаты и обучающие данные, они стремятся способствовать развитию области и позволить другим строить на основе их исследований, способствуя сотрудничеству в моделировании видео-языка.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 42k+ ML SubReddit.
Развивайтесь с помощью искусственного интеллекта
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Demystifying Vision-Language Models: An In-Depth Exploration.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`



















