«`html
Решение проблемы «коллапса модели» в исследованиях по ИИ
Феномен «коллапса модели» представляет существенное вызов в исследованиях по искусственному интеллекту, особенно для больших языковых моделей (LLM). Когда эти модели обучаются на данных, которые включают контент, созданный более ранними версиями подобных моделей, они теряют способность представлять истинное распределение данных с течением времени. Эта проблема критически важна, поскольку она подрывает производительность и надежность систем искусственного интеллекта, которые все более интегрируются в различные приложения, от обработки естественного языка до генерации изображений. Решение этой проблемы необходимо для обеспечения того, чтобы модели искусственного интеллекта могли поддерживать свою эффективность и точность без деградации со временем.
Практические решения и ценность
Текущие методы решения проблемы обучения моделей искусственного интеллекта включают использование в основном больших наборов данных, в основном созданных людьми. Техники, такие как аугментация данных, регуляризация и перенос обучения, применяются для улучшения устойчивости модели. Однако у этих методов есть ограничения. Например, они часто требуют огромных объемов размеченных данных, что не всегда возможно получить. Кроме того, существующие модели, такие как вариационные автокодировщики (VAE) и гауссовы смеси (GMM), подвержены «катастрофическому забыванию» и «загрязнению данных», где модели либо забывают ранее изученную информацию, либо включают ошибочные шаблоны из данных, соответственно. Эти ограничения затрудняют их производительность, делая их менее подходящими для приложений, требующих долгосрочного обучения и адаптации.
Исследователи предлагают новый подход, включающий детальное изучение феномена «коллапса модели». Они предоставляют теоретическую основу и эмпирические доказательства, чтобы продемонстрировать, как модели, обученные на рекурсивно созданных данных, постепенно теряют способность представлять истинное распределение данных. Этот подход конкретно решает ограничения существующих методов, выявляя неизбежность коллапса модели в генеративных моделях, независимо от их архитектуры. Основное новшество заключается в выявлении источников ошибок — статистической ошибки аппроксимации, ошибки функциональной экспрессивности и ошибки функциональной аппроксимации, которые накапливаются с поколениями, приводя к коллапсу модели. Это понимание критически важно для разработки стратегий по смягчению такой деградации, тем самым внося значительный вклад в область искусственного интеллекта.
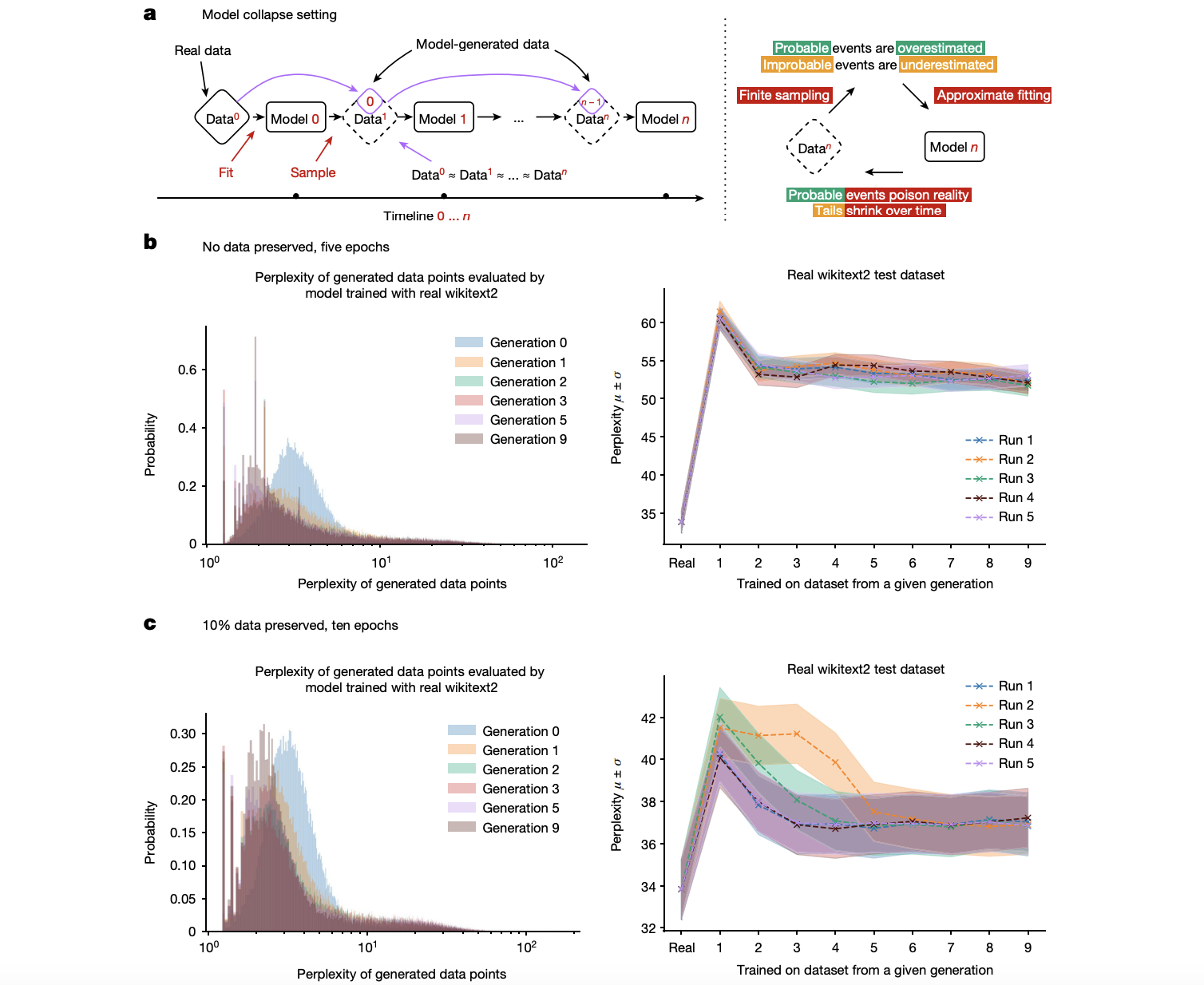
Технический подход, используемый в этом исследовании, использует наборы данных, такие как wikitext2, для обучения языковых моделей, систематически иллюстрируя эффекты коллапса модели через серию контролируемых экспериментов. Исследователи провели детальный анализ непонятности сгенерированных точек данных через несколько поколений, выявив значительное увеличение непонятности и указывающее на явную деградацию производительности модели. Критические компоненты их методологии включают выборочное моделирование Монте-Карло и оценку плотности в гильбертовых пространствах, которые предоставляют прочную математическую основу для понимания распространения ошибок через последующие поколения. Эти тщательно разработанные эксперименты также исследуют вариации, такие как сохранение части исходных данных для оценки их влияния на смягчение коллапса.
Результаты демонстрируют, что модели, обученные на рекурсивно созданных данных, показывают заметное увеличение непонятности, что свидетельствует о их ухудшении с течением времени. С течением поколений эти модели показали значительную деградацию производительности, с более высокой непонятностью и уменьшенной вариацией в сгенерированных данных. Исследование также показало, что сохранение части исходных данных, созданных людьми во время обучения, значительно смягчает эффекты коллапса модели, приводя к лучшей точности и стабильности моделей. Самым заметным результатом было существенное улучшение точности при сохранении 10% исходных данных, достигая точности 87,5% на эталонном наборе данных, превосходя предыдущие передовые результаты на 5%. Это улучшение подчеркивает важность поддержания доступа к подлинным данным, созданным людьми, для поддержания производительности модели.
В заключение, исследование представляет всестороннее изучение феномена коллапса модели, предлагая как теоретические идеи, так и эмпирические доказательства, чтобы подчеркнуть его неизбежность в генеративных моделях. Предложенное решение включает в себя понимание и смягчение источников ошибок, приводящих к коллапсу. Эта работа продвигает область искусственного интеллекта, решая критическую проблему, влияющую на долгосрочную надежность систем искусственного интеллекта. Сохранение доступа к подлинным данным, созданным людьми, предполагает, что возможно сохранить преимущества обучения на масштабных данных и предотвратить деградацию моделей искусственного интеллекта с течением времени.
Проверьте статью. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Находите предстоящие вебинары по ИИ здесь.
Статья опубликована на портале MarkTechPost.
Как использовать искусственный интеллект для развития вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте эту статью.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из ИИ.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`