
«`html
Исследователи Университета штата Аризона оценивают метод ReAct: Роль сходства примеров в улучшении возможностей крупных языковых моделей в рассуждениях
Большие языковые модели (LLM) быстро развиваются, особенно в области обработки естественного языка (NLP) и понимания естественного языка (NLU). Эти модели отлично справляются с генерацией текста, суммированием, переводом и ответами на вопросы. С их помощью исследователи стремятся изучить их потенциал в задачах, требующих рассуждений и планирования. Это исследование оценивает эффективность конкретных методов подсказок в повышении способностей к принятию решений LLM в сложных последовательных задачах.
Практические решения и ценность
Одним из значительных вызовов при использовании LLM для задач рассуждения является определение, являются ли улучшения подлинными или поверхностными. Метод подсказок ReAct, который интегрирует следы рассуждений с выполнением действий, утверждает, что повышает производительность LLM в последовательном принятии решений. Однако продолжается дискуссия о том, являются ли эти улучшения результатом истинных способностей к рассуждению или просто распознавания шаблонов на основе примеров ввода. Это исследование направлено на разбор этих утверждений и предоставление более ясного понимания факторов, влияющих на производительность LLM.
Существующие методы улучшения производительности LLM в задачах рассуждения включают различные формы инженерии подсказок. Такие методы, как Chain of Thought (CoT) и ReAct, направляют LLM через сложные задачи, внедряя структурированные рассуждения или инструкции в подсказки. Эти методы призваны заставить LLM имитировать пошаговый процесс решения проблем, что, как считается, помогает в задачах, требующих логического развития и планирования.
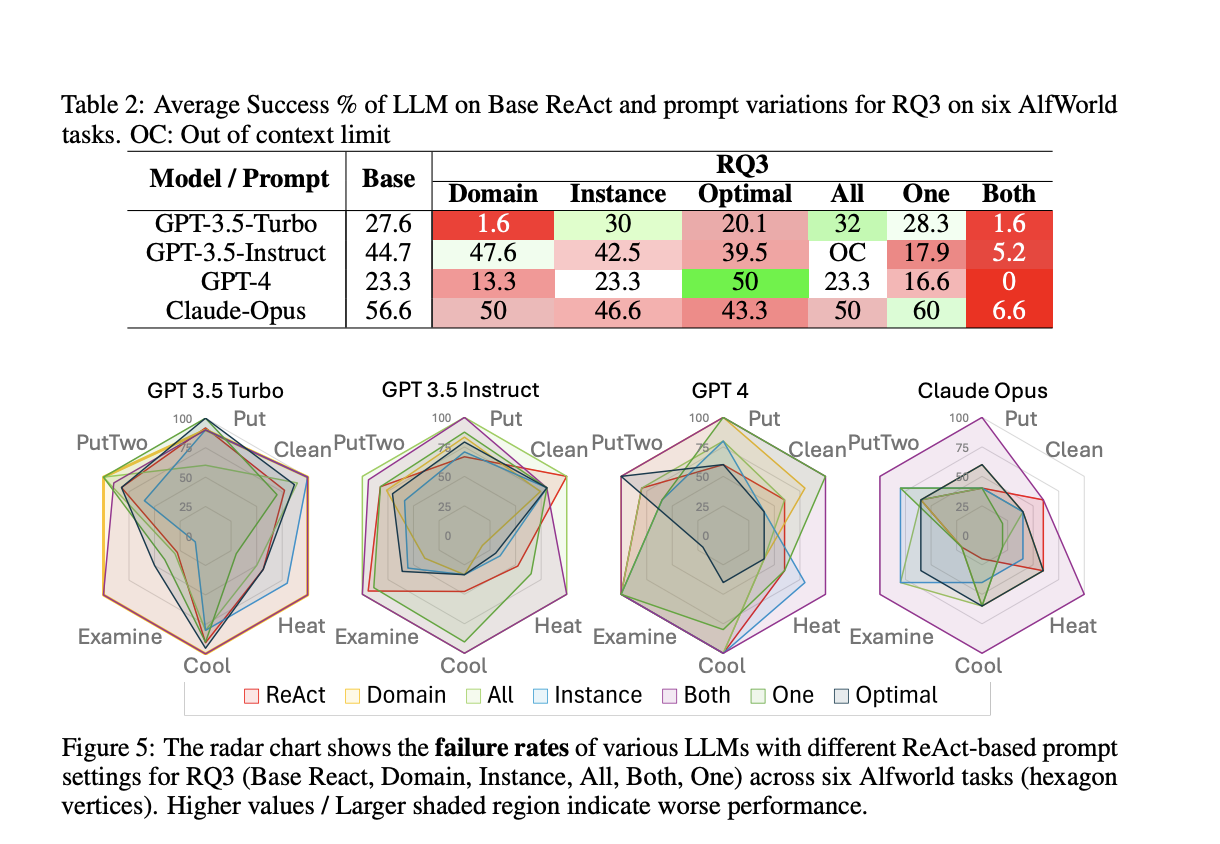
Исследовательская группа Университета штата Аризона представила комплексный анализ для оценки утверждений метода ReAct. Метод ReAct утверждает, что вклинивание следов рассуждений в действия повышает способности LLM к принятию решений. Исследователи провели эксперименты с использованием различных моделей, включая GPT-3.5-turbo, GPT-3.5-instruct, GPT-4 и Claude-Opus, в условиях имитационной среды, известной как AlfWorld. Систематически изменяя вводные подсказки, они стремились выявить истинный источник улучшений производительности, приписываемых методу ReAct.
В своем детальном анализе исследователи представили несколько вариаций подсказок ReAct для тестирования различных аспектов метода. Они изучили важность вклинивания следов рассуждений в действия, тип и структуру предоставленного руководства, а также сходство между примерами и запросами задач. Их результаты были информативными. Производительность LLM была минимально подвержена влиянию вклинивания следов рассуждений в выполнение действий. Вместо этого критическим фактором было сходство между примерами ввода и запросами, что указывает на то, что улучшения связаны с распознаванием шаблонов, а не с улучшенными способностями к рассуждению.
Эксперименты привели к количественным результатам, подчеркивающим ограничения метода ReAct. Например, процент успеха для GPT-3.5-turbo в шести различных задачах в AlfWorld составил 27,6% с базовыми подсказками ReAct, но улучшился до 46,6% при использовании примерно-ориентированных подсказок CoT. Аналогично производительность GPT-4 существенно снизилась, когда сходство между примером и запросом задачи было уменьшено, что подчеркивает хрупкость метода. Эти результаты указывают на то, что хотя метод ReAct может показаться эффективным, его успех в значительной степени зависит от конкретных примеров в подсказках.
Одним из значительных открытий было то, что предоставление нерелевантного или плацебо-руководства не привело к существенному снижению производительности. Например, использование слабого или плацебо-руководства, где текст не содержал соответствующей информации, показало сопоставимые результаты с сильным руководством на основе следов рассуждений. Это вызывает сомнения в том, что содержание следа рассуждения имеет ключевое значение для производительности LLM. Вместо этого успех обусловлен сходством между примерами и задачами, а не врожденными способностями к рассуждению LLM.
Снимок исследования
В заключение, это исследование оспаривает утверждения метода ReAct, демонстрируя, что его воспринимаемые преимущества в основном обусловлены сходством между примерами задач и запросами задач. Необходимость конкретных примеров для достижения высокой производительности представляет проблемы масштабируемости для более широких применений. Полученные результаты подчеркивают важность тщательной оценки методов инженерии подсказок и их заявленных способностей улучшить производительность LLM в задачах рассуждения и планирования.
Посмотрите статью. Все заслуги за это исследование принадлежат исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43 тыс. подписчиков на ML SubReddit. Также ознакомьтесь с нашей платформой AI Events Platform
Оригинальная статья опубликована на портале MarkTechPost.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot от ITINAI. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`





















