
«`html
Решение проблемы координации групп стратегических агентов через рекомендации действий
Проблема:
Основная сложность заключается в том, что невозможно вручную задать качество рекомендаций, требуется предоставление данных для координации. Это приводит к проблеме многозначного обучения по подражанию множественных агентов (MAIL).
Методы решения:
Исследования включают в себя методы одноагентного обучения по подражанию и интерактивные подходы, включая обратное обучение по усилению (RL). Также рассматривается мультиагентное обучение по подражанию и обратная игровая теория, направленная на восстановление функций полезности.
Результаты и выводы:
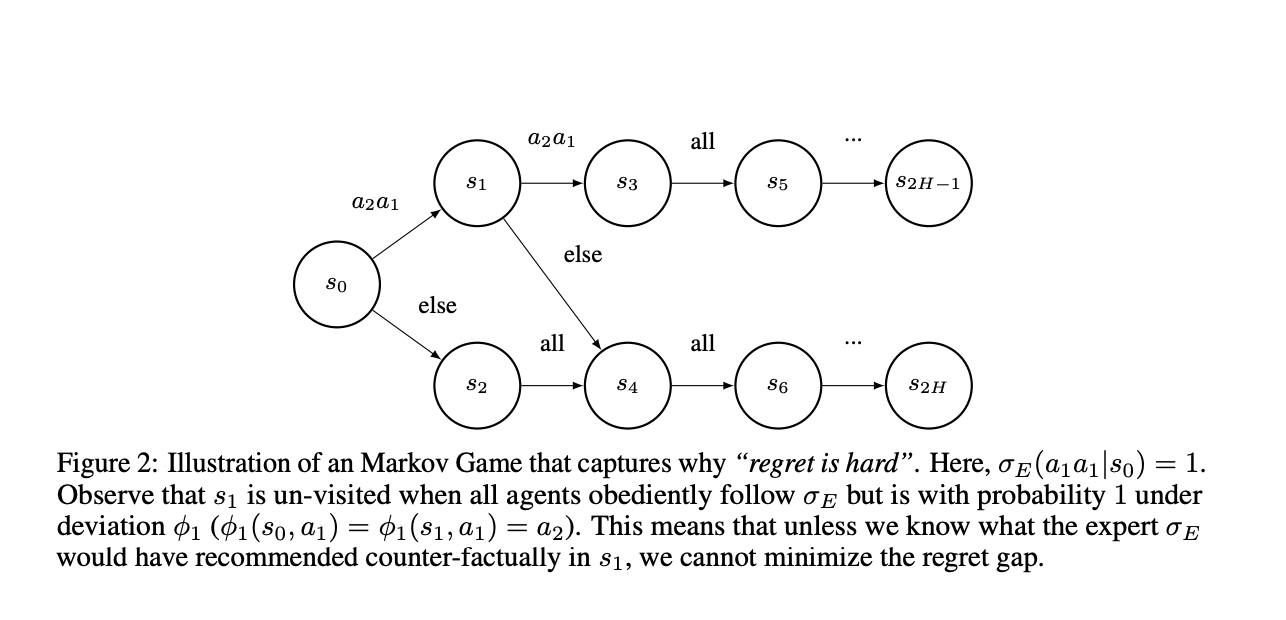
Ученые из университета Карнеги-Меллон предложили альтернативный подход к обучению многозначного обучения по подражанию в марковских играх, называемый разрывом сожаления. Исследование показало, что минимизация разрыва ценности требует различных подходов, чем минимизация разрыва сожаления.
Практические решения:
Работа включает разработку эффективных методов оптимизации и алгоритмов, таких как MALICE и BLADES, для минимизации разрыва сожаления и разрыва ценности в мультиагентной среде.
Будущие перспективы:
Дальнейшая работа включает разработку и внедрение практических приближений этих идеальных алгоритмов.
Мы в социальных сетях:
Не забудьте следить за нами в Twitter и присоединиться к нашему Telegram каналу и группе на LinkedIn, чтобы быть в курсе новостей.
«`



















