
«`html
Исследование стратегий эффективной настройки параметров для больших языковых моделей
Важность использования больших языковых моделей и их параметров
Большие языковые модели (LLM) представляют собой революционный скачок во многих областях применения, обеспечивая впечатляющие достижения в различных задачах. Однако их огромный размер требует значительных вычислительных затрат. С миллиардами параметров эти модели требуют обширных вычислительных ресурсов для работы. Адаптация их к конкретным задачам особенно сложна из-за их огромного масштаба и вычислительных требований, особенно на аппаратных платформах, ограниченных вычислительными возможностями.
Оптимизация производительности LLM
Предыдущие исследования показали, что LLM демонстрируют значительные способности к обобщению, позволяя им применять изученные знания к новым задачам, не встреченным во время обучения, феномен, известный как обучение с нуля. Однако для оптимизации производительности LLM на устойчивых пользовательских наборах данных и задачах остается важной финетюнинг. Одной из широко принятых стратегий финетюнинга является регулирование подмножества параметров LLM, оставляя остальные без изменений, называемое параметрически-эффективный финетюнинг (PEFT). Эта техника выборочно модифицирует небольшую долю параметров, оставляя большинство нетронутыми. Применимость PEFT не ограничивается обработкой естественного языка (NLP) и охватывает интерес к моделям больших параметров, таким как модели Vision Transformers (ViT) и модели диффузии, а также междисциплинарные модели визуального языка.
Исследование и категоризация PEFT алгоритмов
Исследователи из Northeastern University, University of California, Arizona State University и New York University представляют этот обзор, тщательно изучая различные алгоритмы PEFT и оценивая их производительность и вычислительные требования. Они также предоставляют обзор разработанных приложений с использованием различных методов PEFT и обсуждают общие стратегии, используемые для сокращения вычислительных расходов, связанных с PEFT. Кроме алгоритмических соображений, обзор касается дизайнов реальных систем для изучения затрат на реализацию различных алгоритмов PEFT. Как бесценный ресурс, этот обзор снабжает исследователей пониманием алгоритмов PEFT и их системных реализаций, предлагая подробные анализы последних прогрессов и практических применений.
Категоризация алгоритмов PEFT и учет затрат
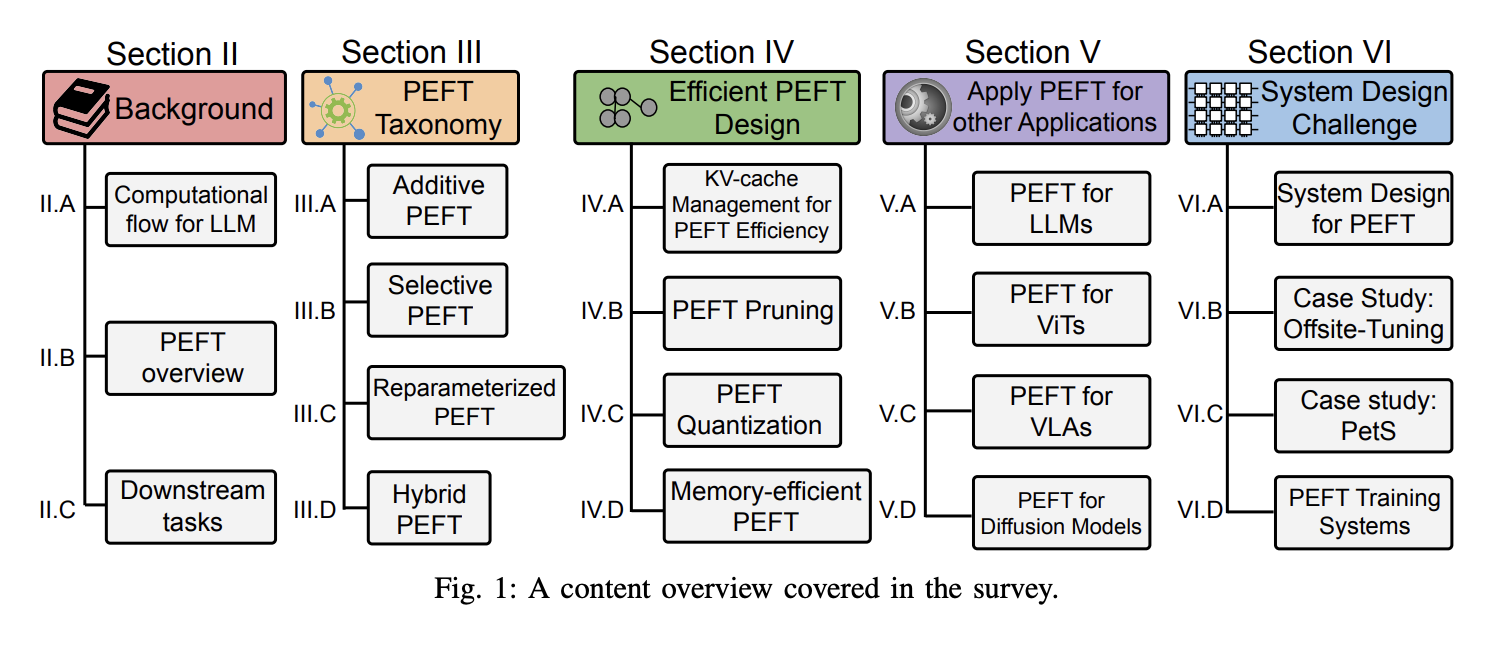
Исследователи категоризировали алгоритмы PEFT на аддитивные, селективные, репараметризованные и гибридные финетюнинги, основанные на их операциях. Крупные аддитивные алгоритмы финетюнинга включают адаптеры, мягкие подсказки и другие, отличающиеся используемыми дополнительными модулями или параметрами. Селективный финетюнинг, напротив, включает выбор небольшого подмножества параметров из базовой модели, делая только эти параметры изменяемыми, оставляя большинство нетронутым во время финетюнинга последующей задачи. Репараметризация включает преобразование параметров модели между двумя эквивалентными формами, вводя дополнительные низкоранговые обучаемые параметры во время обучения, которые затем интегрируются с оригинальной моделью для вывода. Этот подход охватывает две основные стратегии: низкоранговую декомпозицию и производные LoRA. Гибридный финетюнинг исследует различные дизайны PEFT-методов и комбинирует их преимущества.
Исследование вычислительных затрат в LLM
Исследователи установили ряд параметров для изучения затрат на вычисления и излишек памяти в LLM в качестве основы для последующего анализа. В LLM токены (слова) генерируются итеративно на основе предшествующего запроса (ввода) и ранее сгенерированной последовательности. Этот процесс продолжается до тех пор, пока модель не выведет токен завершения. Общей стратегией ускорения вывода в LLM является сохранение предыдущих ключей и значений в кэше KeyValue (KV-кеш), что устраняет необходимость пересчитывать их для каждого нового токена.
Заключение
Этот обзор всесторонне изучает различные алгоритмы PEFT, предоставляя понимание их производительности, применений и затрат на реализацию. Путем категоризации методов PEFT и изучения вычислительных и памяти исследование предлагает бесценное руководство для исследователей, разбирающихся в сложностях финетюнинга больших моделей.
Проверьте статью. Весь заслуги за это исследование принадлежат исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу, Discord и LinkedIn группе.
Если вам нравится наша работа, вам понравится наша новостная рассылка. Не забудьте присоединиться к нашему сообществу на Reddit и оценить AI Sales Bot.
Если у вас есть вопросы или вы хотите получить консультацию по ИИ, напишите нам в Telegram. Следите за новостями о ИИ в нашем Телеграм-канале и в Twitter. Попробуйте AI Sales Bot по ссылке AI Sales Bot. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`





















