
«`html
Исследование AI от Google DeepMind: разрыв в производительности между онлайн и офлайн методами выравнивания
Практические решения и ценность
RLHF — стандартный подход для выравнивания LLMs. Однако, недавние достижения в офлайн методах выравнивания, таких как DPO и его варианты, вызывают сомнения в необходимости онлайн-выравнивания в RLHF. Офлайн методы, которые выравнивают LLMs с использованием существующих наборов данных без активного онлайн-взаимодействия, показали практическую эффективность и являются более простыми и дешевыми в реализации. Это вызывает вопрос о том, является ли онлайн RL неотъемлемым для выравнивания ИИ. Сравнение онлайн и офлайн методов сложно из-за их различных вычислительных требований, что требует тщательной калибровки бюджета, затрачиваемого на измерение производительности, для честной оценки.
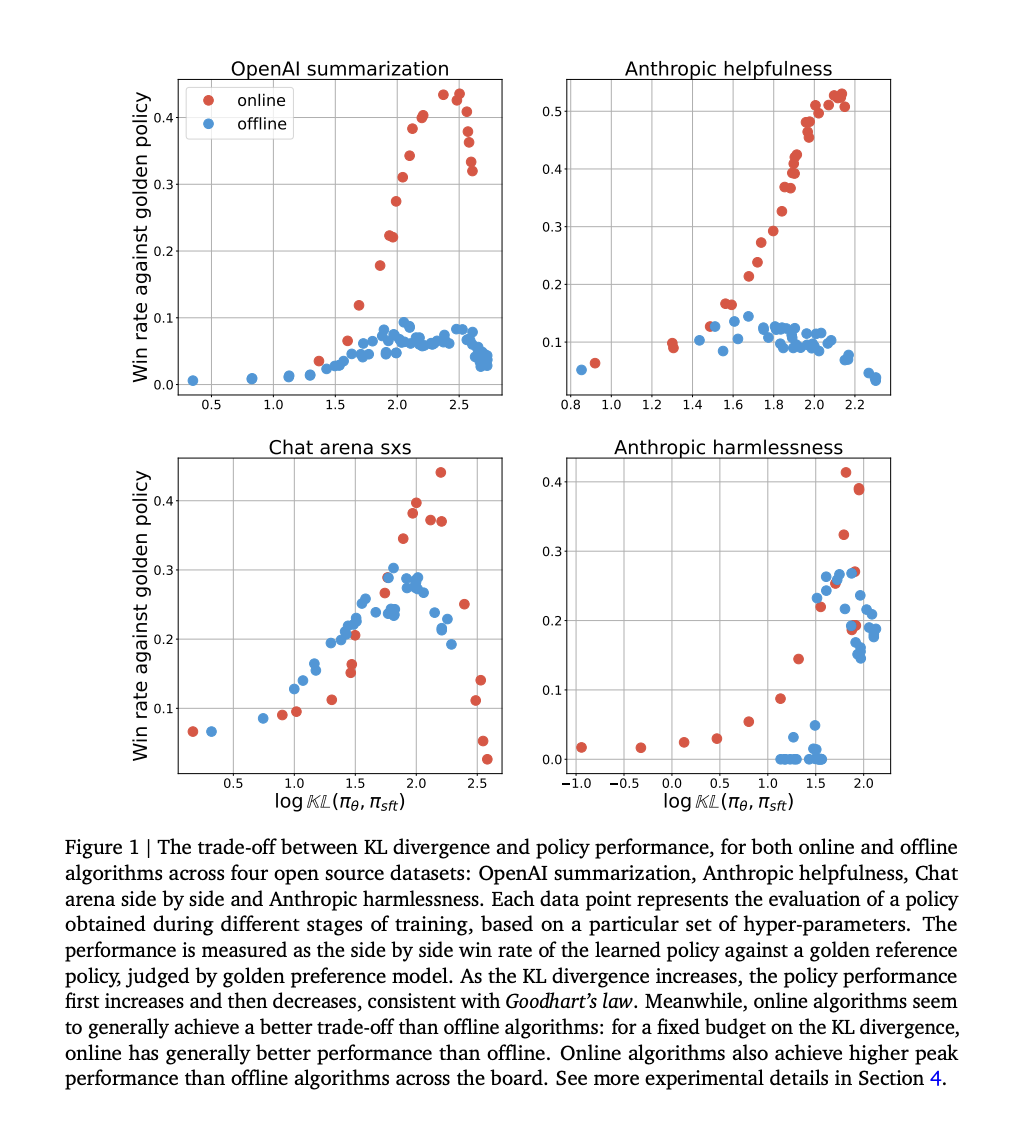
Исследователи из Google DeepMind продемонстрировали, что онлайн методы превосходят офлайн методы в их первоначальных экспериментах, что побудило к дальнейшему изучению этой разницы в производительности. Через контролируемые эксперименты они обнаружили, что факторы, такие как покрытие и качество офлайн данных, должны полностью объяснить разрыв. В отличие от онлайн методов, офлайн методы преуспевают в попарной классификации, но требуют помощи в генерации. Разрыв сохраняется независимо от типа функции потерь и масштабирования модели. Это указывает на то, что онлайн взаимодействие является критическим для выравнивания ИИ, подчеркивая сложности офлайн выравнивания. В исследовании используется дивергенция Кульбака-Лейблера от политики с учителем (SFT), чтобы сравнить производительность алгоритмов при различных бюджетах, что позволяет обнаружить устойчивые различия.
Исследование дополняет предыдущую работу по RLHF, сравнивая онлайн и офлайн алгоритмы RLHF. Исследователи выявляют устойчивый разрыв в производительности между онлайн и офлайн методами, даже при использовании различных функций потерь и масштабировании сетей политики. В то время как предыдущие исследования отмечали сложности в офлайн RL, их результаты подчеркивают, что они применимы и к RLHF.
Исследование сравнивает онлайн и офлайн методы выравнивания с использованием IPO потерь на различных наборах данных, изучая их производительность в рамках закона Гудхарта. IPO потери включают оптимизацию веса выигрышных ответов над проигрышными, а различия в процессах выборки определяют онлайн и офлайн методы. Онлайн алгоритмы выбирают ответы на основе политики, в то время как офлайн алгоритмы используют фиксированный набор данных. Эксперименты показывают, что онлайн алгоритмы достигают лучших компромиссов между дивергенцией Кульбака-Лейблера и производительностью, более эффективно используя бюджет Кульбака-Лейблера и достигая более высокой пиковой производительности. Предлагаются несколько гипотез для объяснения этих различий, таких как разнообразие охвата данных и неоптимальные офлайн наборы данных.
Гипотеза предполагает, что разрыв в производительности между онлайн и офлайн алгоритмами частично обусловлен точностью классификации модели предпочтений по сравнению с самой политикой. Во-первых, модель предпочтений обычно достигает более высокой точности классификации, чем политика при использовании в качестве классификатора. Во-вторых, предполагается, что это различие в точности классификации вносит свой вклад в наблюдаемый разрыв в производительности между онлайн и офлайн алгоритмами. В сущности, это предположение указывает на то, что лучшая классификация приводит к лучшей производительности, но данная гипотеза нуждается в дальнейшем изучении и подтверждении на основе эмпирических данных.
В заключение, исследование подчеркивает критическую роль онлайн взаимодействия для эффективного выравнивания LLMs и выявляет сложности, связанные с офлайн подходами к выравниванию. Исследователи опровергли несколько общепринятых убеждений о разрыве в производительности между онлайн и офлайн алгоритмами через тщательные эксперименты и проверку гипотез. Они подчеркнули важность генерации онлайн-данных для повышения эффективности обучения политики. Однако они также утверждают, что офлайн алгоритмы могут улучшиться, приняв стратегии, имитирующие процессы онлайн-обучения. Это открывает перспективы для дальнейшего исследования, такие как гибридные подходы, объединяющие преимущества онлайн и офлайн методов, а также более глубокие теоретические исследования в области обучения с подкреплением для обратной связи от человека.
Проверьте статью. Все заслуги за это исследование принадлежат исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему Telegram-каналу, Discord-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit с более чем 42 тысячами подписчиков
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru, будущее уже здесь!
«`



















