
Использование искусственного интеллекта (ИИ) в кооперативных задачах: новые возможности и практические решения
Продвижение ИИ через самообучение в играх
Искусственный интеллект достиг значительных успехов благодаря агентам, играющим в игры, таким как AlphaGo, демонстрирующим сверхчеловеческую производительность с помощью самостоятельных игровых техник. Самообучение позволяет моделям улучшаться, обучаясь на данных, созданных в ходе игр против самих себя, что доказало свою эффективность в соревновательных средах, таких как игры в Го и шахматы.
Развитие искусственного интеллекта в кооперативных языковых задачах
Однако существует постоянная проблема в области ИИ — улучшение производительности в сотрудничестве или частично сотрудничающих языковых задачах. В отличие от конкурентных игр, где цель четко очерчена, языковые задачи часто требуют сотрудничества и поддержания человеческой интерпретируемости.
Исследования и практические решения
Существующие исследования включают модели, такие как AlphaGo и AlphaZero, которые используют самообучение для соревновательных игр. Коллективные диалоговые задачи, такие как Cards, CerealBar, OneCommon и DialOp, оценивают модели в кооперативных средах с использованием самообучения в качестве оценки человека. Тем не менее, эти структуры часто сталкиваются с трудностями в поддержании интерпретируемости человеческого языка и не могут эффективно обобщать стратегии в смешанных кооперативных и соревновательных средах, ограничивая их применимость в реальном мире.
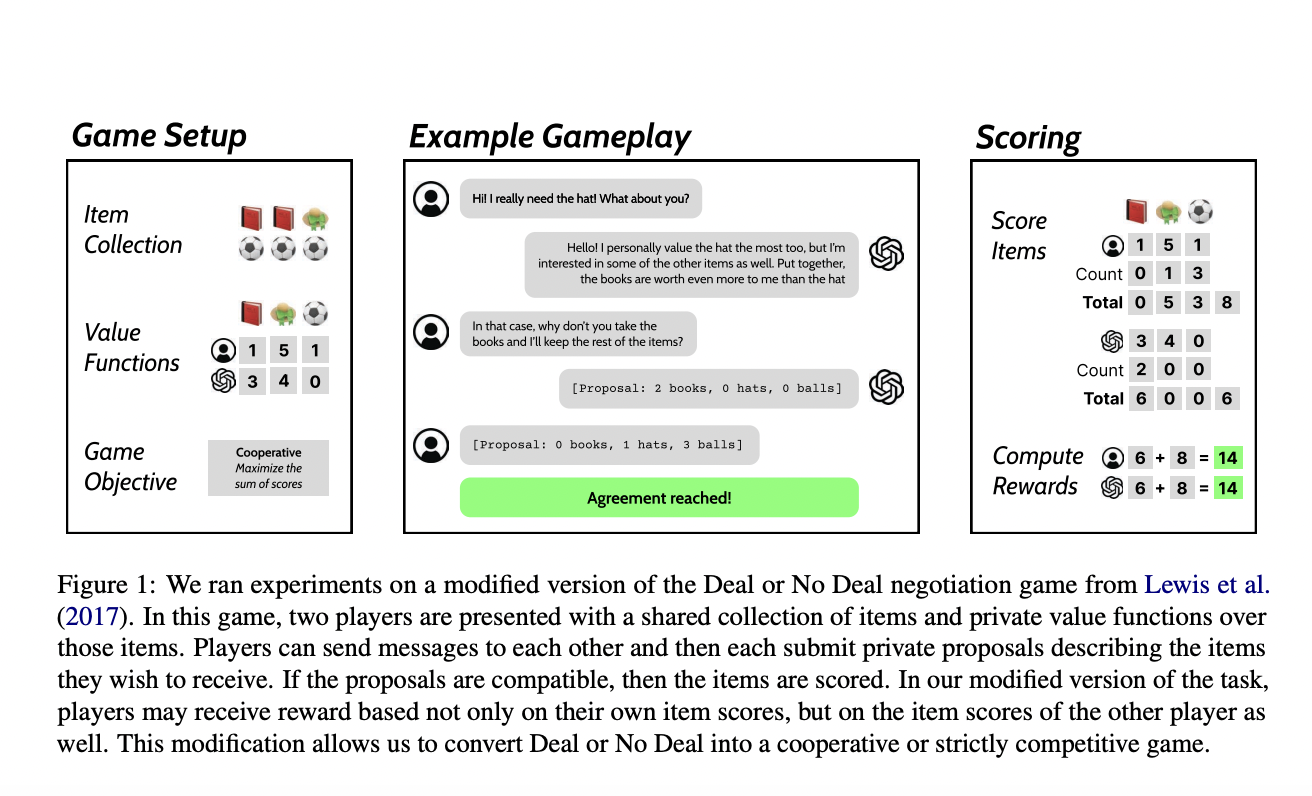
Новый подход к самообучению в кооперативных и соревновательных средах
Исследователи из Университета Калифорнии, Беркли, представили новый подход для тестирования самообучения в кооперативных и соревновательных средах, используя модифицированную версию игры на переговоры «Deal or No Deal» (DoND). Эта игра была адаптирована для поддержки различных целей, делая ее подходящей для оценки улучшений языковых моделей на разных уровнях сотрудничества.
Основные результаты и практические выводы
Обучение через самоигру привело к значительному улучшению производительности моделей в кооперативных и частично соревновательных средах, демонстрируя потенциал самообучения для улучшения способностей языковых моделей к сотрудничеству и соревнованию с людьми. Однако строго соревновательная среда представляет вызовы, поскольку модели часто затрудняются обобщать свои стратегии, не достигая соглашений с другими агентами.
Применение и рекомендации
Это исследование подчеркивает потенциал самообучения в области тренировки языковых моделей для совместных задач. Результаты вызывают сомнения в распространенном предположении о том, что самообучение неэффективно в кооперативных областях или что моделям нужны обширные данные людей для поддержания интерпретируемости языка. Это открывает возможности для широкого применения самообучения за пределами конкурентных игр, потенциально улучшая производительность ИИ в различных коллаборативных задачах.
Проверьте нашу статью и код. Вся благодарность за это исследование принадлежит его авторам. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 45 тыс. подписчиков в ML SubReddit.
Эта статья о применении самообучения для тренировки языковых моделей в кооперативных задачах была опубликована на MarkTechPost.




















