
«`html
Проблемы обучения с подкреплением и новые решения
Обучение с подкреплением (RL) популярно, но сталкивается с трудностями, которые мешают пользователям использовать его потенциал. Например, алгоритмы, такие как PPO, требуют много данных для обучения. Однако методы Off-Policy, такие как SAC и DrQ, помогают решить эту проблему, но имеют свои недостатки.
Проблемы Off-Policy методов
Эти методы часто зависят от плотных сигналов вознаграждения, что снижает их эффективность в условиях редких вознаграждений. Это связано с простыми схемами исследования, такими как ε-жадный и Болтцмановский подход. Несмотря на это, их простота и масштабируемость привлекают пользователей.
Внутреннее исследование и его преимущества
Недавно внутреннее исследование показало большой потенциал, где сигналы вознаграждения, такие как получение информации и любопытство, улучшают исследование агентов RL. Исследования показывают, что максимизация получения информации может значительно улучшить результаты.
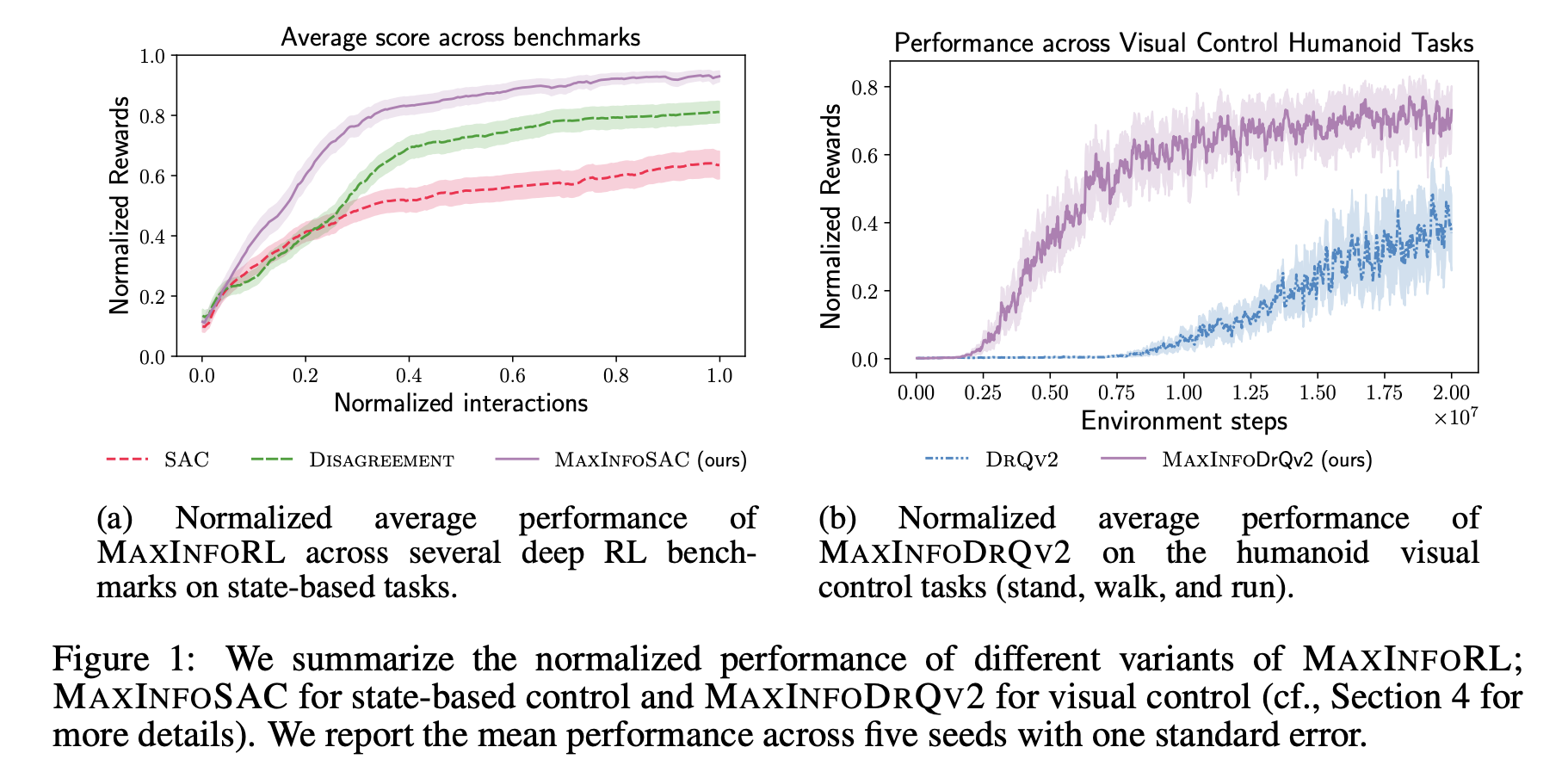
MAXINFORL: новое решение
Исследователи из ETH Цюрих и UC Беркли представили MAXINFORL, который улучшает старые методы исследования и связывает их с внутренними вознаграждениями. Это новый класс алгоритмов Off-Policy, который использует направленное исследование для эффективного решения задач.
Как работает MAXINFORL
MAXINFORL улучшает стандартный Болтцмановский метод исследования, добавляя внутренние вознаграждения. Он использует автоматическую настройку для упрощения баланса между исследованием и вознаграждениями. Алгоритмы, модифицированные MAXINFORL, исследуют пути, достигая максимального получения информации.
Результаты исследований
Команда исследователей протестировала MAXINFORL на нескольких задачах глубокого RL и обнаружила, что он consistently outperform другие методы. Даже в сложных условиях MAXINFORL показал лучшие результаты, значительно улучшив скорость и эффективность.
Заключение
MAXINFORL улучшает наивные методы исследования, достигая внутренних вознаграждений и показывая высокие результаты на различных задачах. Однако, для его работы требуется обучение нескольких моделей, что увеличивает вычислительные затраты.
Как использовать ИИ в вашей компании
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение из множества доступных ИИ.
- Внедряйте ИИ постепенно: начните с малого проекта и анализируйте результаты.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot, который помогает отвечать на вопросы клиентов и снижает нагрузку на первую линию. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`

















