
«`html
FlashInfer: Эффективное решение для вывода больших языковых моделей
Большие языковые модели (LLMs) стали важной частью современных ИИ-приложений, таких как чат-боты и генераторы кода. Однако их использование выявило проблемы в процессах вывода. Механизмы внимания, такие как FlashAttention и SparseAttention, часто сталкиваются с трудностями при работе с разнообразными нагрузками и ограничениями ресурсов GPU. Это подчеркивает необходимость более эффективного решения для поддержки вывода LLM.
Что такое FlashInfer?
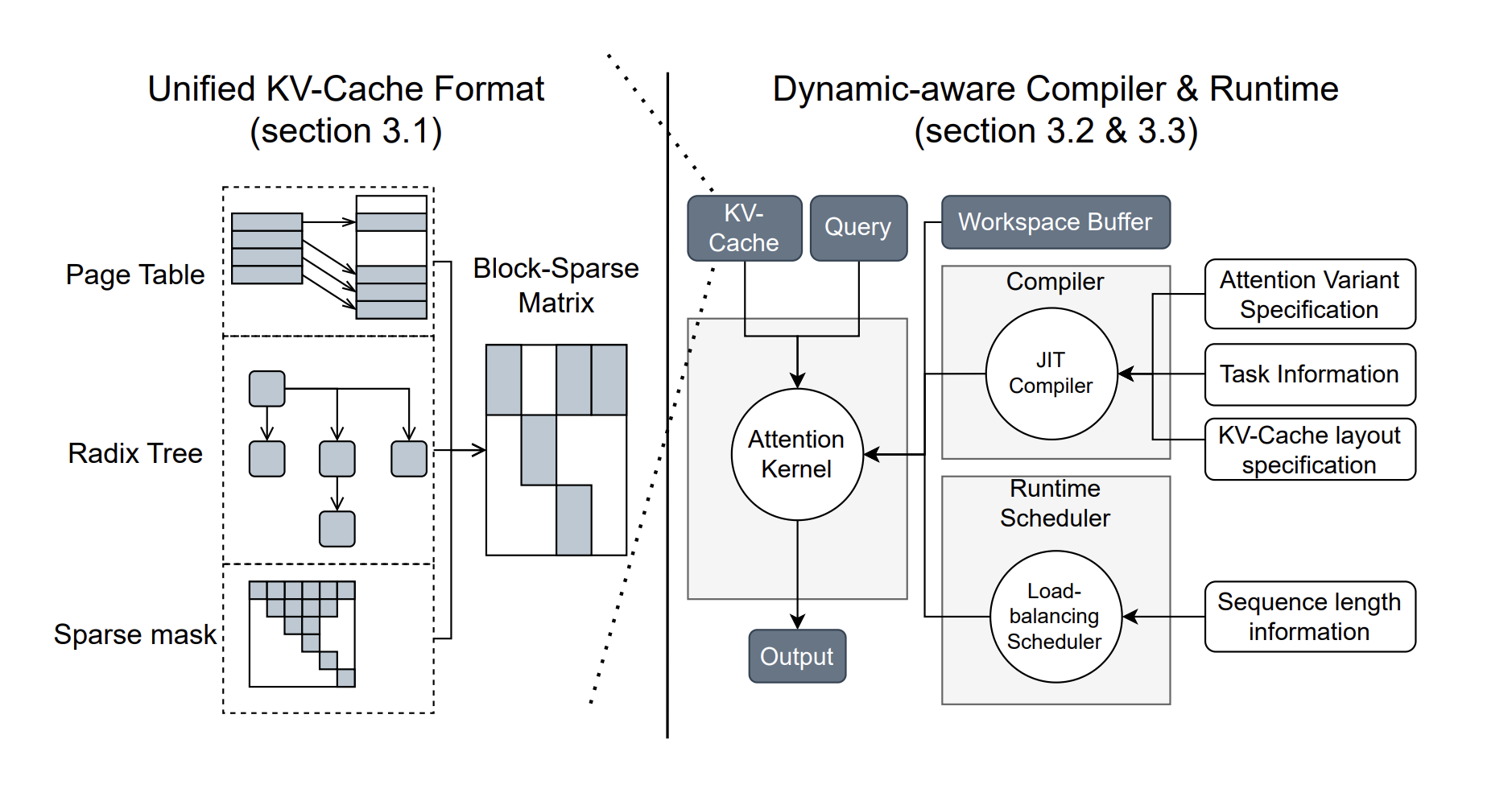
Исследователи из Университета Вашингтона, NVIDIA, Perplexity AI и Университета Карнеги-Меллон разработали FlashInfer — библиотеку ИИ и генератор ядер, специально предназначенный для вывода LLM. FlashInfer предлагает высокопроизводительные реализации ядер для различных механизмов внимания, таких как FlashAttention, SparseAttention и другие.
Преимущества FlashInfer
- Широкий выбор ядер внимания: Поддержка различных механизмов внимания для улучшения производительности.
- Оптимизированное декодирование: Значительное ускорение процессов декодирования, что особенно полезно для длинных запросов.
- Динамическое распределение нагрузки: Эффективное использование ресурсов GPU с минимизацией времени простоя.
- Настраиваемая компиляция: Возможность создания и компиляции пользовательских вариантов внимания для специфических задач.
Показатели производительности
FlashInfer демонстрирует значительные улучшения:
- Снижение задержки: Уменьшение задержки между токенами на 29-69% по сравнению с существующими решениями.
- Увеличение пропускной способности: Ускорение задач параллельного генерации на 13-17% на GPU NVIDIA H100.
- Улучшение использования GPU: Оптимизация пропускной способности и использование FLOP в различных сценариях.
Заключение
FlashInfer предлагает практическое и эффективное решение для проблем вывода LLM, обеспечивая значительные улучшения в производительности и использовании ресурсов. Его гибкий дизайн и возможности интеграции делают его ценным инструментом для развития LLM-сервисов. FlashInfer открывает новые возможности для более доступных и масштабируемых ИИ-приложений.
Как внедрить ИИ в вашу компанию?
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение из множества доступных вариантов.
- Внедряйте ИИ постепенно: начните с небольшого проекта, анализируйте результаты и KPI.
- На основе полученных данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам в Telegram. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter.
Попробуйте AI Sales Bot — этот ИИ-ассистент помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab.
«`

















