
«`html
Введение в метод MeCo
Предварительное обучение языковых моделей (ЯМ) играет важную роль в их способности понимать и генерировать текст. Однако существует проблема: как эффективно использовать разнообразие обучающих данных, включая информацию из Википедии, блогов и социальных сетей.
Модели обычно рассматривают все входные данные одинаково, не учитывая контекстуальные подсказки о источниках или стиле. Это приводит к двум основным недостаткам:
Недостатки текущих подходов:
- Упущенные контекстуальные сигналы: Без учета метаданных, таких как URL источника, модели пропускают важную информацию о намерении или качестве текста.
- Неэффективность в специализированных задачах: Однородное обращение с разными данными может снизить эффективность модели в решении задач, требующих специфических знаний.
Решение от исследователей Принстонского университета
Исследователи предложили метод Metadata Conditioning then Cooldown (MeCo), который использует доступные метаданные, такие как URL источника, в процессе предварительного обучения.
Этапы работы MeCo:
- Стадия Метаданных (первые 90%): К документу добавляется метадата, например, «URL: wikipedia.org», что помогает модели распознавать связь между метаданными и содержанием.
- Стадия Острожности (последние 10%): Обучение продолжается без метаданных, чтобы модель могла обобщать на ситуации, когда метаданные недоступны.
Преимущества метода MeCo
- Улучшение эффективности данных: Использование MeCo позволяет достичь того же уровня производительности с использованием на 33% меньше данных.
- Повышенная адаптивность модели: Модели, обученные с MeCo, могут выдавать результаты с желаемыми атрибутами, такими как большая фактическая точность или меньшая токсичность.
- Минимальные затраты: MeCo практически не добавляет сложности в процесс обучения.
Результаты и выводы
Метод MeCo показал лучшие результаты в различных задачах, таких как ответ на вопросы и проверка логического мышления. Например:
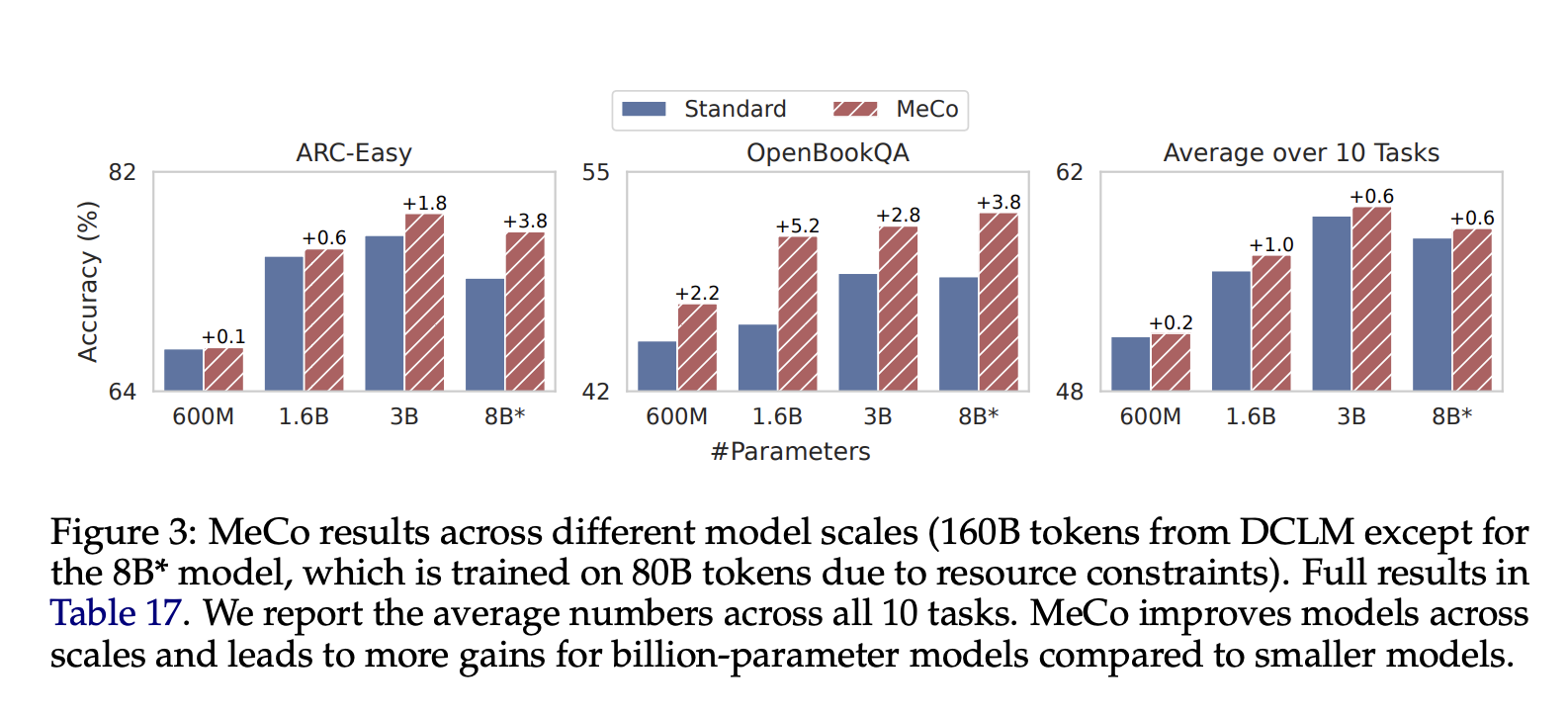
- Модель с 1,6 млрд параметров, обученная на наборе данных DCLM, показала средний прирост производительности на 1% по сравнению со стандартными методами.
- Сокращение токсичности генерируемых ответов с помощью метаданных.
Заключение
Метод MeCo — это практический и эффективный способ оптимизации предварительного обучения языковых моделей. Используя метаданные, MeCo улучшает производительность и адаптивность моделей, а также снижает требования к данным. Простота и минимальные вычислительные затраты делают его привлекательным для разработчиков.
Если вы хотите, чтобы ваша компания использовала ИИ и оставалась конкурентоспособной, рассмотрите возможность применения метода MeCo. Анализируйте, где можно использовать автоматизацию с помощью ИИ, определите ключевые показатели эффективности и внедряйте решения постепенно.
Если вам нужны советы по внедрению ИИ, пишите нам. Следите за новостями о ИИ в нашем Телеграм-канале и других социальных сетях.
«`





















