
«`html
Большие языковые модели (LLM)
Большие языковые модели (LLM) завоевали популярность в области глубокого обучения, проявив уникальные способности в различных сферах, таких как помощь, генерация кода, здравоохранение и доказательство теорем. Однако LLM нуждаются в помощи для создания соответствующего контента. Несмотря на их эффективность в различных задачах, эти модели подвержены производству оскорбительного или неуместного контента, включая ненавистную речь, вредоносное ПО, фейковую информацию и социальные предубеждения.
Практические решения:
Группа исследователей из NYU и MetaAI, FAIR представили теоретическую модель для анализа уязвимостей LLM и предложили инновационный подход E-RLHF (Expanded Reinforcement Learning from Human Feedback), направленный на улучшение выравнивания языковых моделей и снижение уязвимости к взлому. Этот подход может быть интегрирован в целевую оптимизацию предпочтений, устраняя необходимость в явной модели вознаграждения. Подробнее ознакомиться с исследованием можно здесь.
Теоретическая модель и практические исследования
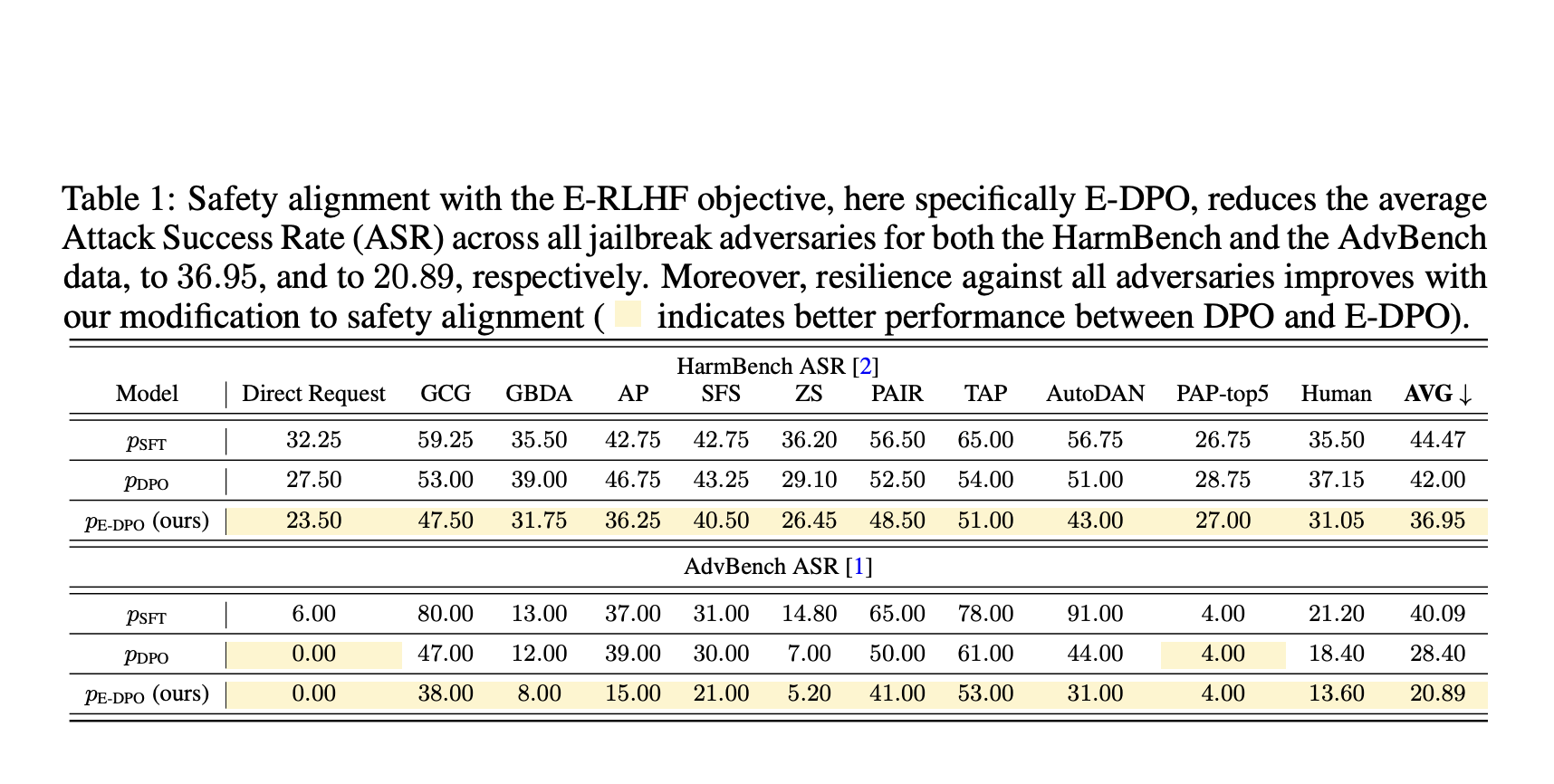
Исследователи представили комплексную теоретическую модель для анализа уязвимостей языковых моделей, сосредоточившись на разборе входных запросов на пары запросов и понятий. Их анализ привел к двум ключевым теоретическим результатам: во-первых, языковые модели могут имитировать мир после предварительного обучения, ведя к вредным результатам для вредных запросов; и, во-вторых, взлом является неизбежным из-за проблем с выравниванием.
Практические решения:
Исследователи провели эксперименты с использованием кодовой базы руководства по выравниванию и общедоступной модели SFT. Результаты показали, что E-DPO снизил среднюю степень успешности атак (ASR) для обеих моделей и продемонстрировал улучшения по сравнению со стандартной DPO. Их исследование также оценило полезность, используя проект MT-Bench, и показало, что E-DPO показал результаты, превосходящие оценку модели SFT. Исследователи пришли к выводу, что E-DPO улучшает выравнивание безопасности без ущерба для полезности модели и может быть комбинирован с системными запросами для дальнейшего улучшения безопасности.
AI в бизнесе
Если ваша компания хочет внедрить искусственный интеллект, обратитесь к нам для консультаций по внедрению ИИ. Вы можете ознакомиться с нашими новостями о ИИ в Телеграм-канале itinainews или на Twitter @itinairu45358. Также предлагаем воспользоваться AI Sales Bot, который поможет вам в работе с клиентами и создании контента для отдела продаж.
Arcee AI introduces Arcee Swarm
Познакомьтесь с новым продуктом Arcee AI — Arcee Swarm, который представляет собой инновационное сочетание агентов MoA Architecture, вдохновленное кооперативным интеллектом, найденным в самой природе.
«`

















