
«`html
Масштабирование искусственного интеллекта (ИИ) в зависимости от размера данных: новый класс индивидуализированных законов масштабирования данных для машинного обучения
Модели машинного обучения для обработки изображений и языка недавно показали значительные улучшения благодаря увеличению размеров моделей и большому количеству высококачественных данных для обучения. Исследования показывают, что больше данных для обучения предсказуемо улучшает модели, что приводит к законам масштабирования, объясняющим связь между уровнем ошибок и размером набора данных. Однако эти законы рассматривают набор данных в целом, не учитывая отдельные примеры обучения. Это ограничение, поскольку некоторые данные более ценны, чем другие, особенно в шумных наборах данных, собранных из интернета. Поэтому важно понимать, как каждая точка данных или источник влияет на обучение модели.
Практические решения и ценность
Существующие работы обсуждают метод, называемый Законы масштабирования для глубокого обучения, который стал популярным в последние годы. Эти законы помогают понять компромиссы между увеличением данных для обучения и размером модели, предсказывать производительность больших моделей и сравнивать, насколько хорошо различные алгоритмы обучения работают на меньших масштабах. Второй подход фокусируется на том, как отдельные точки данных могут улучшить производительность модели. Эти методы обычно оценивают примеры обучения на основе их маргинального вклада. Они могут идентифицировать неправильно помеченные данные, отфильтровывать высококачественные данные, увеличивать вес полезных примеров и выбирать перспективные новые точки данных для активного обучения.
Исследователи из Стэнфордского университета предложили новый подход, изучая масштабирование значения отдельных точек данных. Они обнаружили, что вклад точки данных в производительность модели предсказуемо уменьшается по мере увеличения размера набора данных, следуя логарифмическому закону. Однако это уменьшение варьируется среди точек данных, что означает, что некоторые точки более полезны в меньших наборах данных, в то время как другие становятся более ценными в больших наборах данных. Кроме того, были представлены оценщик максимального правдоподобия и амортизированный оценщик для эффективного изучения этих индивидуальных закономерностей на основе небольшого количества шумных наблюдений для каждой точки данных.
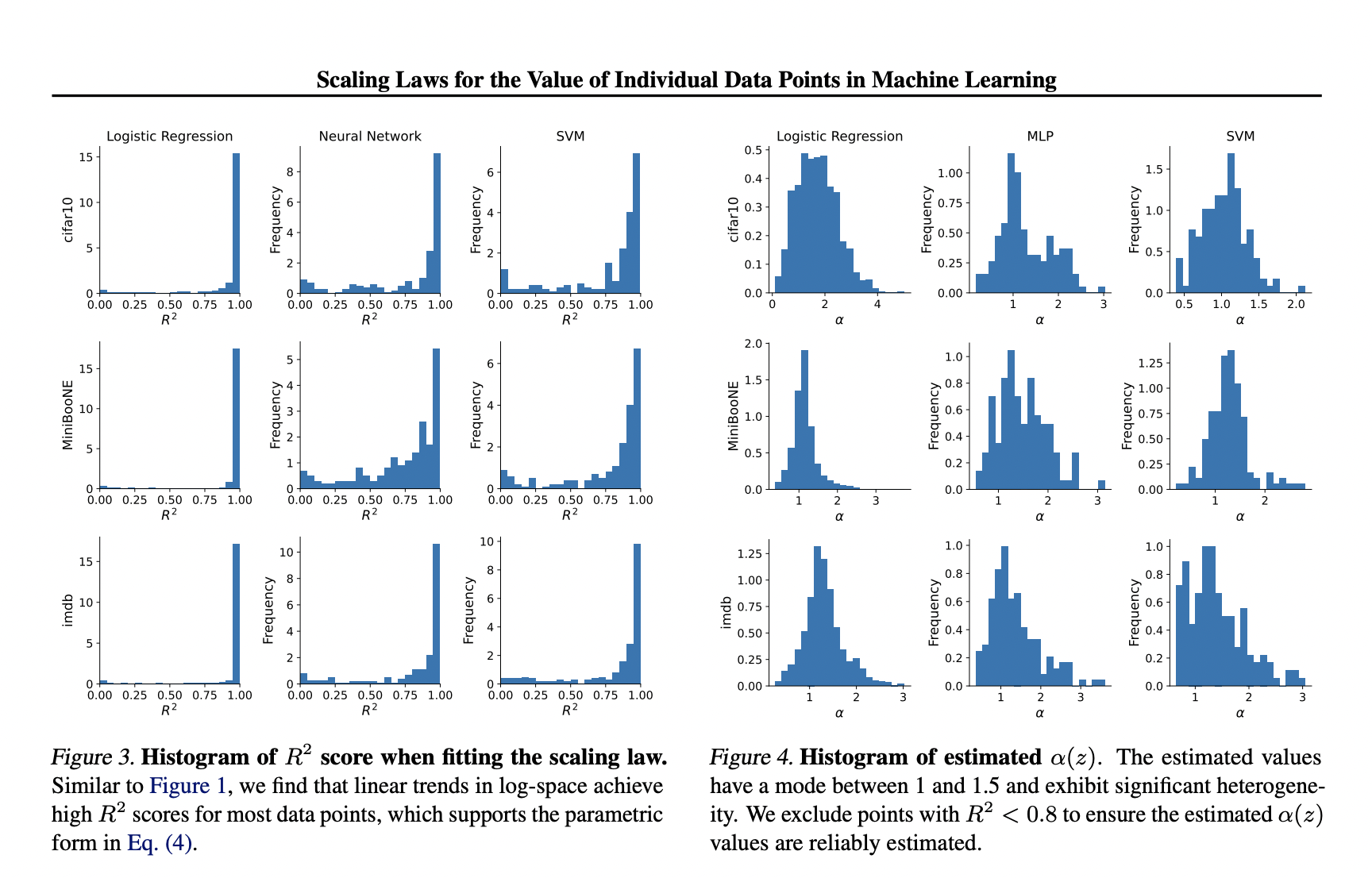
Эксперименты проводились для подтверждения параметрического закона масштабирования, сосредоточившись на трех типах моделей: логистической регрессии, SVM и MLP (в частности, двухслойных сетях ReLU). Эти модели были протестированы на трех наборах данных: MiniBooNE, CIFAR-10 и обзорах фильмов IMDB. Предварительно обученные вложения, такие как замороженные ResNet-50 и BERT, использовались для ускорения обучения и предотвращения недообучения для CIFAR-10 и IMDB, соответственно. Производительность каждой модели измерялась с использованием потерь перекрестной энтропии на тестовом наборе данных из 1000 образцов. Для логистической регрессии использовались 1000 точек данных и 1000 образцов для каждого значения k. Для SVM и MLP из-за большей дисперсии маргинальных вкладов использовались 200 точек данных и 5000 образцов для каждого размера набора данных k.
Предложенные методы были протестированы на предсказание точности маргинальных вкладов для каждого размера набора данных. Например, с набором данных IMDB и логистической регрессией ожидания могут точно предсказываться для размеров набора данных от k = 100 до k = 1000. Для систематической оценки точности предсказаний законов масштабирования показаны результаты по различным размерам набора данных для обеих версий оценщика на основе правдоподобия с использованием различных образцов. Более подробная версия этих результатов показывает снижение оценки R2 при расширении предсказаний за пределы k = 2500, в то время как корреляция и ранговая корреляция с истинными ожиданиями остаются высокими.
В заключение, исследователи из Стэнфордского университета разработали новый метод, изучая, как меняется ценность отдельных точек данных при масштабировании. Они нашли доказательства простой закономерности, которая работает на различных наборах данных и типах моделей. Эксперименты подтвердили этот закон масштабирования, показав четкую логарифмическую тенденцию и проверив, насколько хорошо он предсказывает вклады при различных размерах набора данных. Закон масштабирования может быть использован для предсказания поведения для более крупных наборов данных, чем те, которые изначально тестировались. Однако измерение этого поведения для всего набора данных обучения дорого, поэтому исследователи разработали способы измерения параметров масштабирования с использованием небольшого количества шумных наблюдений на каждую точку данных.
Практические решения в области искусственного интеллекта
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте эту статью.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь, какие ключевые показатели эффективности (KPI) вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`


















