
«`html
Исследование в области вычислительной лингвистики
Исследование в области вычислительной лингвистики продолжает исследовать, как большие языковые модели (LLM) могут быть адаптированы для интеграции новых знаний без ущерба для целостности существующей информации. Одним из ключевых вызовов является обеспечение точности этих моделей, фундаментальных для различных приложений обработки языка, даже при расширении их баз знаний.
Новый подход к интеграции новых знаний
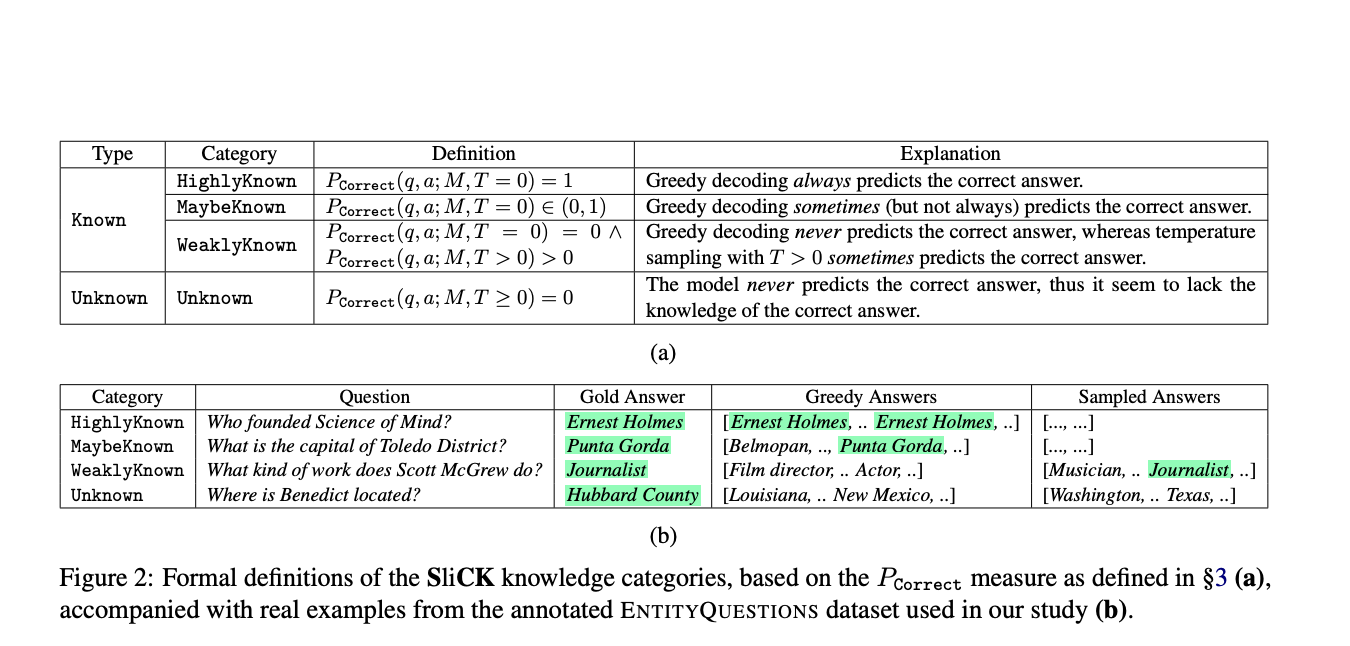
Исследовательская группа из Техниона — Института технологий Израиля и Google Research представила SliCK, новую методику, специально разработанную для изучения интеграции новых знаний в LLM. Этот подход выделяется тем, что он категоризирует знания на различные уровни, начиная от Высокоизвестных до Неизвестных, обеспечивая детальный анализ того, как различные типы информации влияют на производительность модели. Такая настройка позволяет точно оценить способность модели усваивать новые факты, сохраняя при этом точность существующей базы знаний, подчеркивая тонкое равновесие, необходимое при обучении модели.
Экспериментальное исследование
В рамках методики исследование использует модель PaLM, надежную LLM, разработанную Google, которая была тщательно дообучена с использованием наборов данных, тщательно разработанных для включения различных долей категорий знаний: Высокоизвестных, Возможно известных, Слабо известных и Неизвестных. Эти наборы данных происходят из отобранного подмножества фактических вопросов, сопоставленных с отношениями Wikidata, что позволяет контролируемо изучать динамику обучения модели. Эксперимент тщательно количественно оценивает производительность модели по этим категориям, используя метрики точного совпадения (EM), чтобы оценить, насколько эффективно модель интегрирует новую информацию, избегая ложных представлений. Такой структурированный подход предоставляет ясное представление о влиянии дообучения как с знакомыми, так и новыми данными на точность модели.
Выводы и рекомендации
Результаты исследования демонстрируют эффективность категоризации SliCK в улучшении процесса дообучения. Модели, обученные с использованием этого структурированного подхода, особенно смеси из 50% Известных и 50% Неизвестных, показали оптимизированное равновесие, достигнув на 5% более высокой точности в генерации правильных ответов по сравнению с моделями, обученными с преимущественно Неизвестными данными. В то же время, когда доля Неизвестных данных превышала 70%, склонность моделей к ложным представлениям увеличивалась примерно на 12%. Эти результаты подчеркивают критическую роль SliCK в количественной оценке и управлении риском ошибок при интеграции новой информации в процессе дообучения LLM.
Заключение
Исследование Техниона — Института технологий Израиля и Google Research тщательно изучает дообучение LLM с использованием методики SliCK для управления интеграцией новых знаний. Результаты подчеркивают важность стратегической категоризации данных для улучшения надежности и производительности модели, предлагая ценные идеи для будущих разработок методик машинного обучения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с более чем 42 тысячами подписчиков.
Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию. AI Sales Bot
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. itinai.ru будущее уже здесь!
«`





















