
«`html
Как улучшить точность и достоверность языковых моделей при помощи искусственного интеллекта (ИИ)
Проблема:
Языковые модели имеют тенденцию генерировать правдоподобные, но неверные ответы на запросы, что подрывает их надежность и приводит к ограниченной применимости в прикладных задачах, основанных на знаниях.
Решение:
Исследователи из университетов Carnegie Mellon и Stanford обнаружили, что точность языковых моделей улучшается при использовании хорошо закодированных фактов в процессе донастройки моделей. Это позволяет выбирать такие данные, которые улучшают фактическую точность моделей.
Практическое применение:
Использование синтетических данных для изучения влияния донастройки моделей на их точность. Это позволяет контролировать процессы предварительного обучения, что было бы невозможно с реальными большими языковыми моделями.
Результаты:
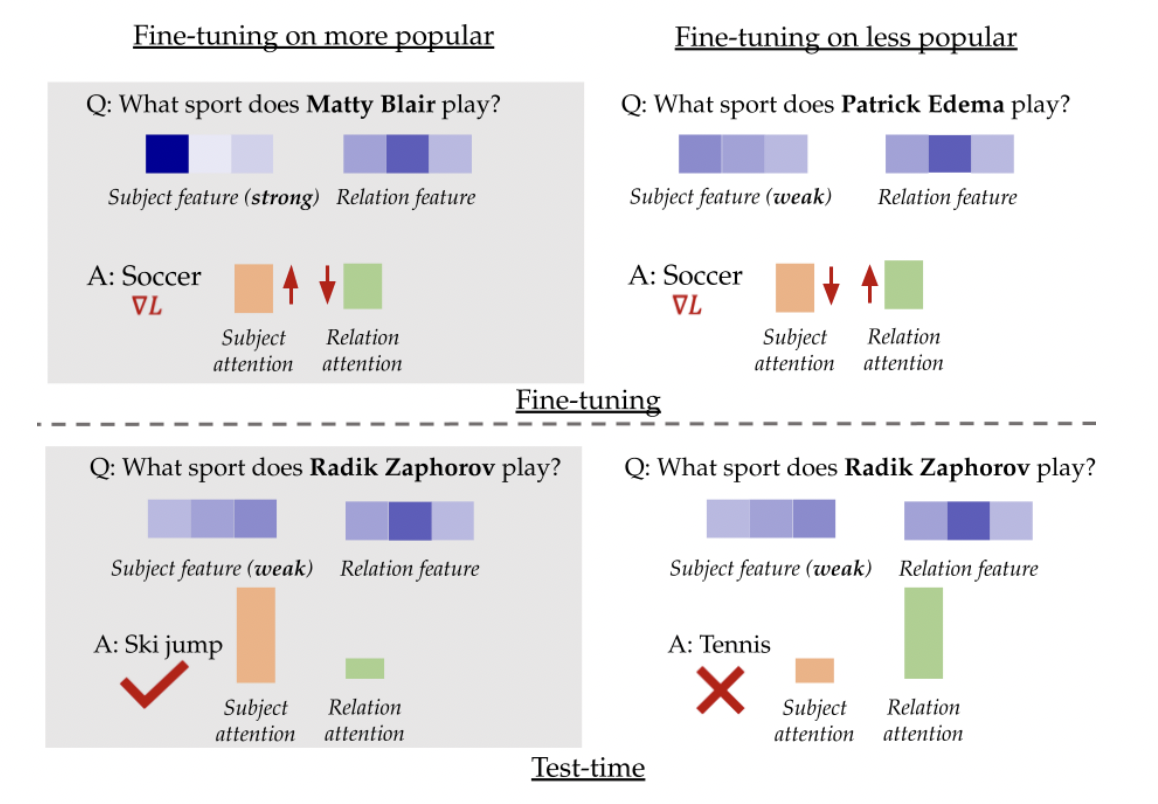
Экспериментальные результаты на различных наборах данных и моделях показывают, что донастройка на менее популярных или менее уверенных примерах даёт худшие результаты по сравнению с использованием популярных знаний. Тщательный выбор данных для донастройки, с фокусом на хорошо известных фактах, может привести к улучшению фактической точности языковых моделей.
Заключение:
Исследование предоставляет значительные инсайты в улучшение фактической точности языковых моделей через стратегическое составление наборов данных для вопросно-ответных систем. Эти результаты могут привести к созданию более эффективных техник обучения и улучшению надёжности языковых моделей в различных областях применения.
Подробнее о исследовании можно узнать здесь.
Вся заслуга за это исследование принадлежит его авторам. Подписывайтесь на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится и наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу на Reddit.
«`




















