
Решение проблемы нестабильности в глубоком обучении с подкреплением
Проблема:
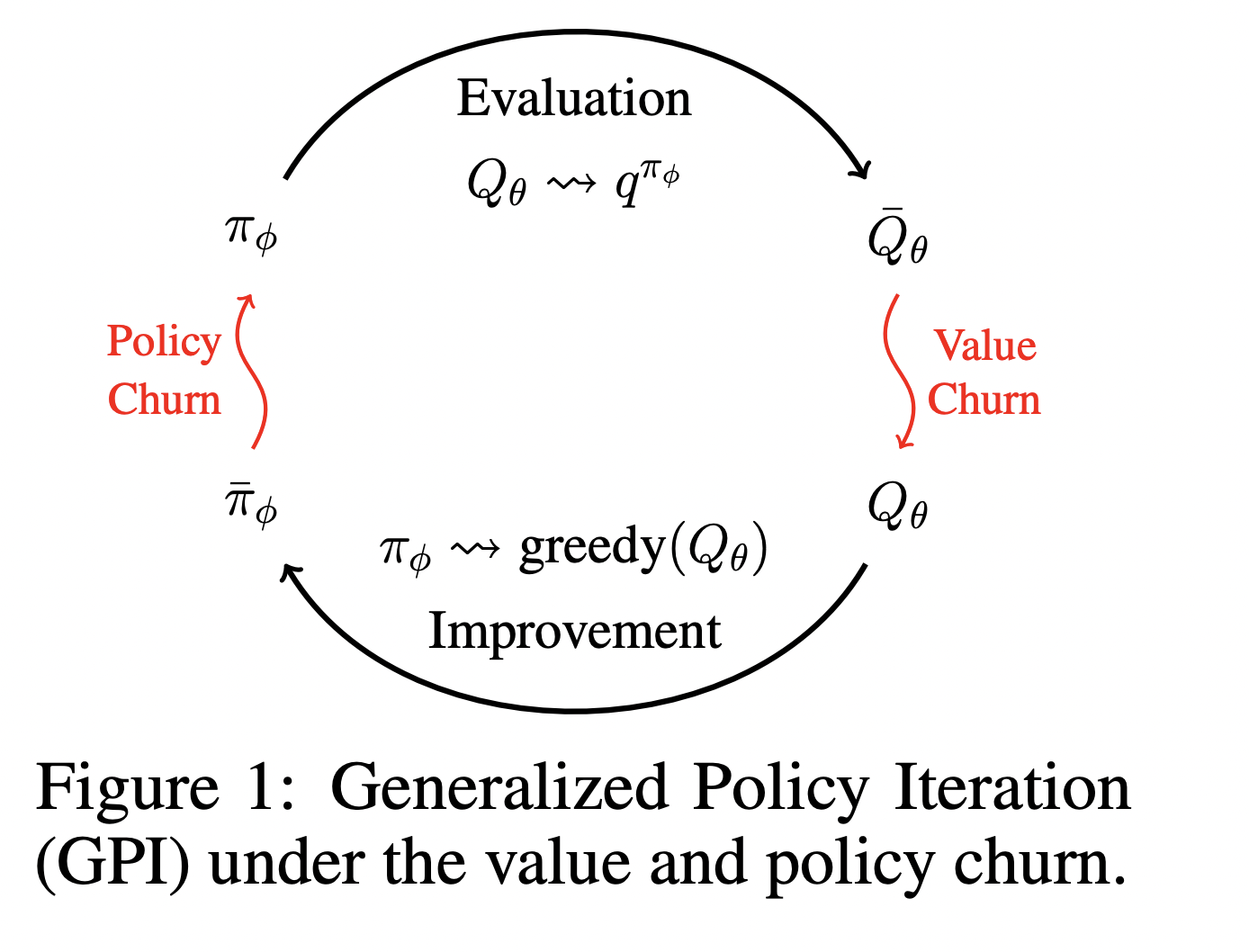
В глубоком обучении с подкреплением (DRL) нестабильность вызывает «churn» во время обучения. Это приводит к непредсказуемым изменениям в выходных данных нейронных сетей для состояний, которые не включены в обучающий набор. Это создает значительные неустойчивости в обучении, что может привести к неэффективности и даже к катастрофическим сбоям.
Решение:
Исследователи из Университета Монреаля представляют метод CHAIN (Churn Approximated ReductIoN), который снижает неустойчивость значения и политики путем введения регуляризационных потерь во время обучения. CHAIN улучшает стабильность алгоритмов обучения на основе значений и политики, привнося простоту и возможность интеграции во многие существующие методы DRL.
Преимущества:
Метод CHAIN значительно улучшает устойчивость обучения и производительность в различных средах, таких как MinAtar, OpenAI MuJoCo и DeepMind Control Suite. Его легкость интеграции и применения делает его универсальным решением для различных алгоритмов DRL, обеспечивая стабильное обучение и повышенную эффективность выборки.




















