
«`html
Понимание уровня галлюцинаций в языковых моделях: исследование обучения на графах знаний и вызовы их обнаружения
Языковые модели (LM) проявляют улучшенную производительность с увеличением размера и объема обучающих данных, однако связь между масштабом модели и галлюцинациями остается неизученной. Определение галлюцинаций в LM представляет сложности из-за их разнообразных проявлений. Новое исследование от Google Deepmind сосредотачивается на галлюцинациях, когда правильные ответы появляются дословно в обучающих данных. Достижение низких уровней галлюцинаций требует более крупных моделей и большего объема вычислительных ресурсов, чем ранее считалось. Обнаружение галлюцинаций становится все более сложным с увеличением размера LM. Графы знаний (KG) предлагают многообещающий подход к предоставлению структурированных фактических данных для обучения LM, потенциально смягчая галлюцинации.
Практические решения и ценность
Исследование рассматривает взаимосвязь масштаба языковой модели (LM) и галлюцинаций, сосредотачиваясь на случаях, когда правильные ответы присутствуют в обучающих данных. Используя набор данных на основе графа знаний (KG), исследователи обучают все более крупные LM для эффективного контроля содержания обучения. Находки указывают на то, что более крупные, дольше обученные LM галлюцинируют меньше, однако достижение низких уровней галлюцинаций требует значительно больше ресурсов, чем ранее считалось. Исследование также выявляет обратную зависимость между масштабом LM и обнаружимостью галлюцинаций.
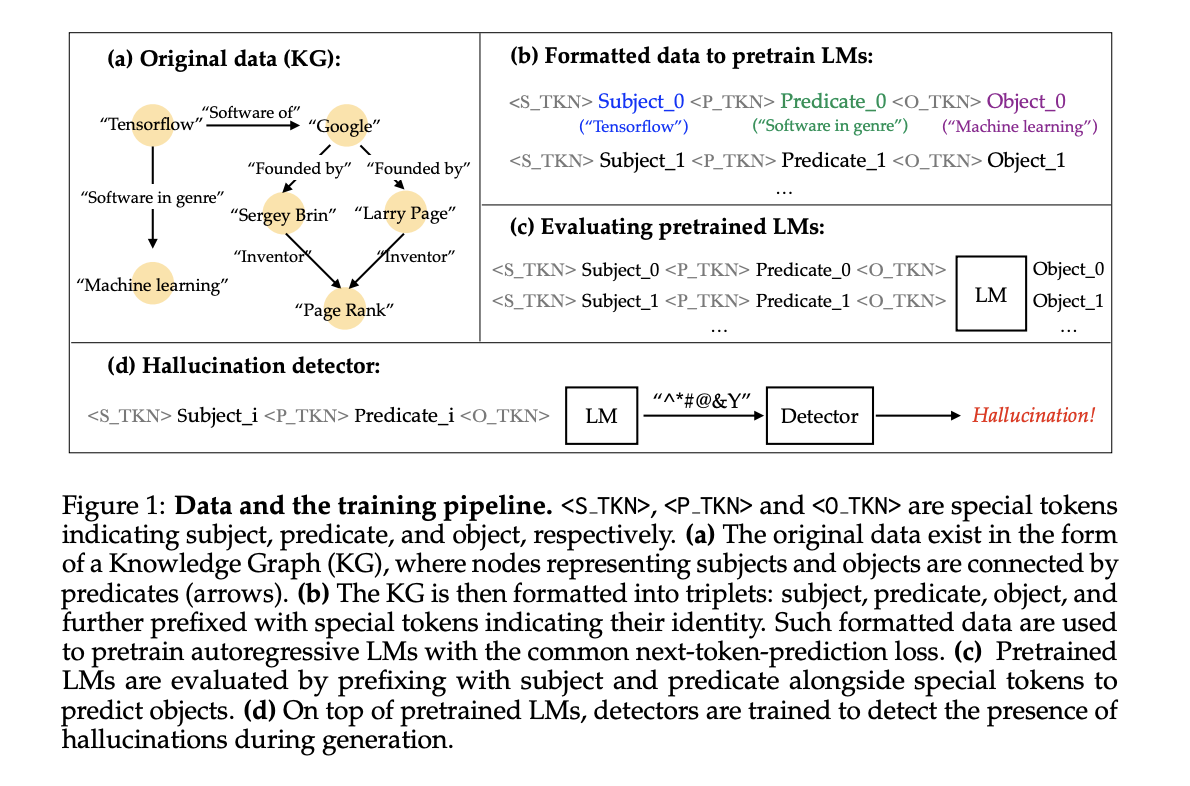
Традиционные языковые модели (LM), обученные на данных естественного языка, часто производят галлюцинации и повторяющуюся информацию из-за семантической неоднозначности. Исследование использует подход на основе графа знаний (KG), используя структурированные тройки информации для более ясного понимания того, как LM искажают обучающие данные. Этот метод позволяет более точно оценивать галлюцинации и их взаимосвязь с масштабом модели.
Исследование создает набор данных, используя тройки графа знаний (субъект, предикат, объект), обеспечивая точный контроль над обучающими данными и количественную оценку галлюцинаций. Языковые модели (LM) обучаются с нуля на этом наборе данных, оптимизируя авторегрессивное логарифмическое правдоподобие. Оценка включает подачу моделям субъекта и предиката, и оценку точности завершения объекта по сравнению с графом знаний. Задачи токенов и детекторы головы оценивают производительность обнаружения галлюцинаций. Методология сосредотачивается на галлюцинациях, где правильные ответы появляются дословно в обучающем наборе данных, исследуя взаимосвязь между масштабом LM и частотой галлюцинаций.
Исследование обучает все более крупные LM для изучения эффектов масштаба на уровни галлюцинаций и их обнаружимость. Анализ показывает, что более крупные, дольше обученные LM галлюцинируют меньше, хотя более крупные наборы данных могут увеличить уровни галлюцинаций. Авторы признают ограничения обобщаемости ко всем типам галлюцинаций и использование моделей меньшего размера, чем современные. Этот комплексный подход предоставляет понимание галлюцинаций LM и их обнаружимости, внося вклад в область обработки естественного языка.
Исследование показывает, что более крупные языковые модели и продленное обучение снижают уровни галлюцинаций на фиксированных наборах данных, в то время как увеличение размера набора данных повышает уровни галлюцинаций. Детекторы галлюцинаций показывают высокую точность, улучшаясь с увеличением размера модели. Обнаружение на уровне токенов в целом превосходит другие методы. Существует компромисс между воспроизведением фактов и способностью обобщения, при продленном обучении минимизирующем галлюцинации на видимых данных, но рискуя переобучением на невидимых данных. AUC-PR служит надежной мерой производительности детектора. Эти результаты подчеркивают сложную взаимосвязь между масштабом модели, размером набора данных и уровнями галлюцинаций, подчеркивая важность балансировки размера модели и продолжительности обучения для смягчения галлюцинаций и решения вызовов, предъявляемых более крупными наборами данных.
В заключение, исследование показывает, что более крупные, дольше обученные языковые модели проявляют сниженные уровни галлюцинаций, однако достижение минимальных уровней галлюцинаций требует значительных вычислительных ресурсов. Увеличение размера набора данных коррелирует с более высокими уровнями галлюцинаций, когда размер модели и количество эпох обучения остаются постоянными. Существует компромисс между запоминанием и обобщением, при продленном обучении улучшающем сохранение фактов, но потенциально затрудняющем адаптацию к новым данным. Парадоксально, по мере увеличения размера моделей и уменьшения галлюцинаций, обнаружение оставшихся галлюцинаций становится более сложным. Будущие исследования должны сосредоточиться на улучшении обнаружения галлюцинаций в более крупных моделях и изучении практических последствий этих результатов для приложений языковых моделей.
Проверьте статью. Вся заслуга за это исследование принадлежит его исследователям. Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наш бюллетень.
Не забудьте присоединиться к нашему подпреддиту ML.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI представляет Arcee Swarm: революционное смешение агентов MoA Architecture, вдохновленное кооперативным интеллектом, обнаруженным в самой природе
Статья опубликована на портале MarkTechPost.
«`



















