
«`html
Оптимизация крупномасштабного сравнения предложений: как Sentence-BERT (SBERT) сокращает вычислительное время, сохраняя высокую точность в задачах семантической текстовой схожести
Исследователи сфокусировались на разработке и построении моделей для эффективной обработки и сравнения человеческого языка в естественной обработке языка. Одной из ключевых областей исследования являются вставки предложений, которые преобразуют предложения в математические векторы для сравнения их семантических значений. Эта технология критически важна для семантического поиска, кластеризации и задач вывода естественного языка. Модели, обрабатывающие такие задачи, могут значительно улучшить системы вопрос-ответ, разговорные агенты и классификацию текста. Однако, несмотря на прогресс в этой области, масштабируемость остается ключевой проблемой, особенно при работе с большими наборами данных или приложениями в реальном времени.
Проблемы обработки текста
Значительная проблема обработки текста возникает из-за вычислительной сложности сравнения предложений. Традиционные модели, такие как BERT и RoBERTa, установили новые стандарты для сравнения пар предложений, но они по своей природе медленны для задач, требующих обработки больших наборов данных. Например, поиск наиболее похожей пары предложений в коллекции из 10 000 предложений с использованием BERT требует около 50 миллионов вычислительных операций, что может занять до 65 часов на современных GPU. Недостаточная эффективность данных моделей создает значительные преграды для масштабирования анализа текста. Это затрудняет их применение в системах реального времени, что делает их непрактичными для многих крупномасштабных приложений, таких как веб-поиск или автоматизация поддержки клиентов.
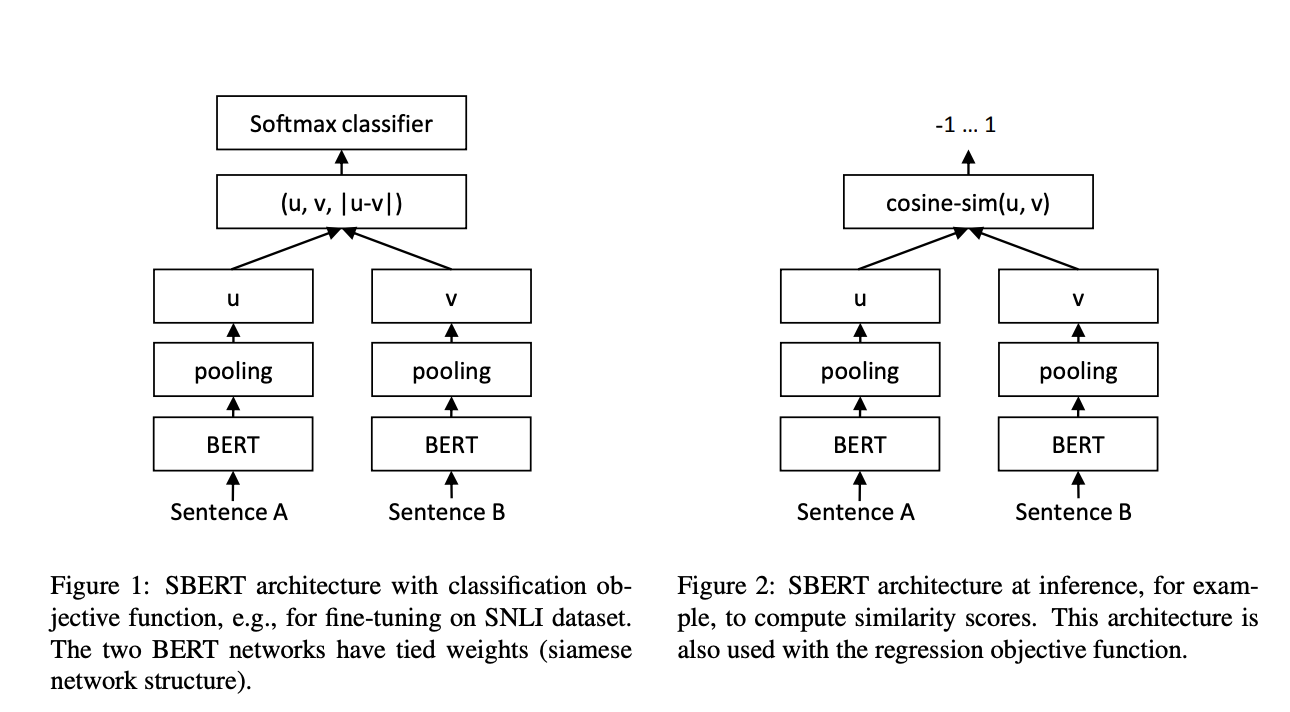
Появление SBERT
Исследователи из Ubiquitous Knowledge Processing Lab (UKP-TUDA) в Департаменте компьютерных наук Технического университета Дармштадта представили Sentence-BERT (SBERT), модификацию модели BERT, разработанную для обработки вставок предложений более вычислительно эффективным способом. Модель SBERT использует архитектуру сети Сиамского типа, которая позволяет сравнивать вставки предложений с использованием эффективных методов подобия, таких как косинусное подобие. Научно-исследовательская группа оптимизировала SBERT для снижения вычислительного времени при сравнении предложений в крупномасштабных задачах, сокращая время обработки с 65 часов до всего пяти секунд для набора из 10 000 предложений. SBERT достигает этой удивительной эффективности, сохраняя уровни точности BERT, доказывая, что скорость и точность могут быть сбалансированы в задачах сравнения пар предложений.
Преимущества SBERT
Основное преимущество SBERT заключается в его способности масштабировать задачи сравнения предложений, сохраняя высокую точность. Например, он может сократить время поиска наиболее похожего вопроса в большом наборе данных, таком как Quora, с более чем 50 часов с BERT до нескольких миллисекунд с SBERT. Эта эффективность достигается благодаря оптимизированным структурам сетей и эффективным методам подобия. SBERT превосходит другие модели в задачах кластеризации, делая его идеальным для проектов анализа текста крупного масштаба. В вычислительных бенчмарках SBERT обрабатывал до 2042 предложений в секунду на GPU, что на 9% больше, чем InferSent, и на 55% быстрее, чем Universal Sentence Encoder.
Заключение
В заключение, SBERT значительно улучшает традиционные методы вставки предложений, предлагая вычислительно эффективное и высокоточное решение. Сокращая время, необходимое для задач сравнения предложений с часов до секунд, SBERT решает критическую проблему масштабируемости в естественной обработке языка. Его превосходная производительность по нескольким бенчмаркам, включая STS и задачи переноса знаний, делает его ценным инструментом для исследователей и практиков. Благодаря своей скорости и точности, SBERT обречен стать важной моделью для анализа текста крупномасштабных, обеспечивая быстрый и надежный семантический поиск, кластеризацию и другие задачи естественной обработки языка.
Источник изображения: [Image Source]
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru — будущее уже здесь!
FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
The post Optimizing Large-Scale Sentence Comparisons: How Sentence-BERT (SBERT) Reduces Computational Time While Maintaining High Accuracy in Semantic Textual Similarity Tasks appeared first on MarkTechPost.
«`



















